i want to select the whole row in which the minimal value of 3 selected columns is found, in a dataframe like this:
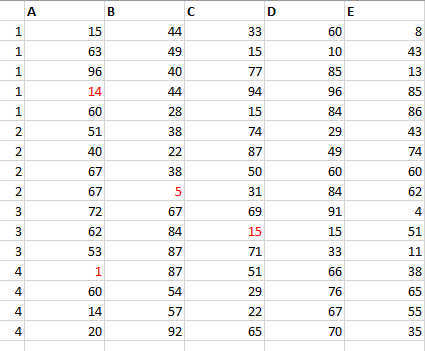
it is supposed to look like this afterwards:
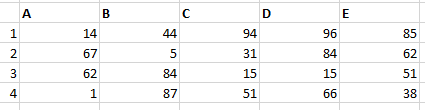
I tried something like
dfcheckminrow = dfquery[dfquery == dfquery['A':'C'].min().groupby('ID')]
obviously it didn't work out well.
Thanks in advance!
CodePudding user response:
One method do filter the initial DataFrame based on a groupby conditional could be to use transform to find the minimum for a "ID" group and then use loc to filter the initial DataFrame where `any(axis=1) (checking rows) is met.
# create sample df
df = pd.DataFrame({'ID': [1, 1, 2, 2, 3, 3],
'A': [30, 14, 100, 67, 1, 20],
'B': [10, 1, 2, 5, 100, 3]})
# set "ID" as the index
df = df.set_index('ID')
Sample df:
A B
ID
1 30 10
1 14 1
2 100 2
2 67 5
3 1 100
3 20 3
Use groupby and transform to find minimum value based on "ID" group.
Then use loc to filter initial df to where any(axis=1) is valid
df.loc[(df == df.groupby('ID').transform('min')).any(axis=1)]
Output:
A B
ID
1 14 1
2 100 2
2 67 5
3 1 100
3 20 3
In this example only the first row should be removed as it in both columns is not a minimum for the "ID" group.
CodePudding user response:
Bkeesey's answer looks like it almost got you to your solution. I added one more step to get the overall minimum for each group.
import pandas as pd
# create sample df
df = pd.DataFrame({'ID': [1, 1, 2, 2, 3, 3],
'A': [30, 14, 100, 67, 1, 20],
'B': [10, 1, 2, 5, 100, 3],
'C': [1, 2, 3, 4, 5, 6],
})
# set "ID" as the index
df = df.set_index('ID')
# get the min for each column
mindf = df[['A','B']].groupby('ID').transform('min')
# get the min between columns and add it to df
df['min'] = mindf.apply(min, axis=1)
# filter df for when A or B matches the min
df2 = df.loc[(df['A'] == df['min']) | (df['B'] == df['min'])]
print(df2)
In my simplified example, I'm just finding the minimum between columns A and B. Here's the output:
A B C min
ID
1 14 1 2 1
2 100 2 3 2
3 1 100 5 1