I have a file which has header at first row and then other data at remaining rows. I want to check whether all rows has equal no of data with header.
For example: if header has 10 count then I want all my remaining rows to have 10 data each so there will be no error while loading the data.
Suppose in line 5 and 6 there are only 5 data each.So,i want to combine these two rows in such case.

My expected output is(Row 5 has the merged data)

There may such breakable data in many rows of the file.So, i just want to scan whole file and will merge the two rows when such cases are seen.
So, I tried using:
$splitway=' '
$firstLine = Get-Content -Path $filepath -TotalCount 1
$firstrowheader=$firstLine.split($splitway,System.StringSplitOptions]::RemoveEmptyEntries)
$requireddataineachrow=$firstrowheader.Count
echo $requireddataineachrow
The above code will give me 10 since my header is having 10 data.
For ($i = 1; $i -lt $totalrows; $i ) {
$singleline=Get-Content $filepath| Select -Index $i
$singlelinesplit=$singleline.split($splitway,[System.StringSplitOptions]::RemoveEmptyEntries)
if($singlelinesplit.Count -lt $requireddataineachrow){
$curr=Get-Content $filepath| Select -Index $i
$next=Get-Content $filepath| Select -Index $i 1
Write-Host (-join($curr, " ", $next))
}
echo $singlelinesplit.Count
}
I tested using Write-Host (-join($curr, " ", $next)) to join two lines but it's not giving the correct output.
echo $singlelinesplit.Count is showing correct result:
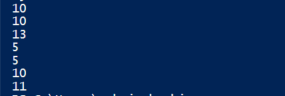
My whole data is:
billing summary_id offer_id vendor_id import_v system_ha rand_dat mand_no sad_no cad_no
11 23 44 77 88 99 100 11 12 500
1111 2333 4444 6666 7777777 8888888888 8888888888888 9999999999 1111111111111 2000000000
33333 444444 As per new account ddddddd gggggggggggg wwwwwwwwwww bbbbbbbbbbb qqqqqqqqqq rrrrrrrrr 5555555
22 33 44 55 666<CR>
42 65 66 55 244
11 23 44 76 88 99 100 11 12 500
1111 2333 new document 664466 7777777 8888888888 8888888888888 9999999999 111111144111 200055000
My whole code if needed is:
cls
$filepath='D:\test.txt'
$splitway=' '
$totalrows=@(Get-Content $filepath).Length
write-host $totalrows.gettype()
$firstLine = Get-Content -Path $filepath -TotalCount 1
$firstrowheader=$firstLine.split($splitway,[System.StringSplitOptions]::RemoveEmptyEntries)
$requireddataineachrow=$firstrowheader.Count
For ($i = 1; $i -lt $totalrows; $i ) {
$singleline=Get-Content $filepath| Select -Index $i
$singlelinesplit=$singleline.split($splitway,[System.StringSplitOptions]::RemoveEmptyEntries)
if($singlelinesplit.Count -lt $requireddataineachrow){
$curr=Get-Content $filepath| Select -Index $i
$next=Get-Content $filepath| Select -Index $i 1
Write-Host (-join($curr, " ", $next))
}
echo $singlelinesplit.Count
}
CodePudding user response:
Update: It seems that instances of string <CR> are a verbatim part of your input file, in which case the following solution should suffice:
(Get-Content -Raw sample.txt) -replace '<CR>\s*', ' ' | Set-Content sample.txt
Here's a solution that makes the following assumptions:
<CR>is just a placeholder to help visualize an actual newline in the input file.Only data rows with fewer columns than the header row require fixing (as Mathias points out, your data is ambiguous, because a column value such as
As per new accounttechnically comprises three values, due to its embedded spaces).Such a data row can blindly be joined with the subsequent line (only) to form a complete data row.
# Create a sample file.
@'
billing summary_id offer_id vendor_id import_v system_ha rand_dat mand_no sad_no cad_no
11 23 44 77 88 99 100 11 12 500
1111 2333 4444 6666 7777777 8888888888 8888888888888 9999999999 1111111111111 2000000000
33333 444444 As per new account ddddddd gggggggggggg wwwwwwwwwww bbbbbbbbbbb qqqqqqqqqq rrrrrrrrr 5555555
22 33 44 55 666
42 65 66 55 244
11 23 44 76 88 99 100 11 12 500
1111 2333 new document 664466 7777777 8888888888 8888888888888 9999999999 111111144111 200055000
'@ > sample.txt
# Read the file into the header row and an array of data rows.
$headerRow, $dataRows = Get-Content sample.txt
# Determine the number of whitespace-separated columns.
$columnCount = (-split $headerRow).Count
# Process all data rows and save the results back to the input file:
# Whenever a data row with fewer columns is encountered,
# join it with the next row.
$headerRow | Set-Content sample.txt
$joinWithNext = $false
$dataRows |
ForEach-Object {
if ($joinWithNext) {
$partialRow ' ' $_
$joinWithNext = $false
}
elseif ((-split $_).Count -lt $columnCount) {
$partialRow = $_
$joinWithNext = $true
}
else {
$_
}
} | Add-Content sample.txt