So, i'm trying to navigate into a pharmacy web site with Selenium (Python). This web site provides a catalog of thousands medicines and health products.
Im trying to do an "horizontal" web scraping, extracting the links for every single product in every page of the catalog (at this moment i can do that).
The problem came when i'm trying to advance to the next page of the catalog, i don't have a click button and the URL doesn't change.
url: 
And the HTML have the next path:
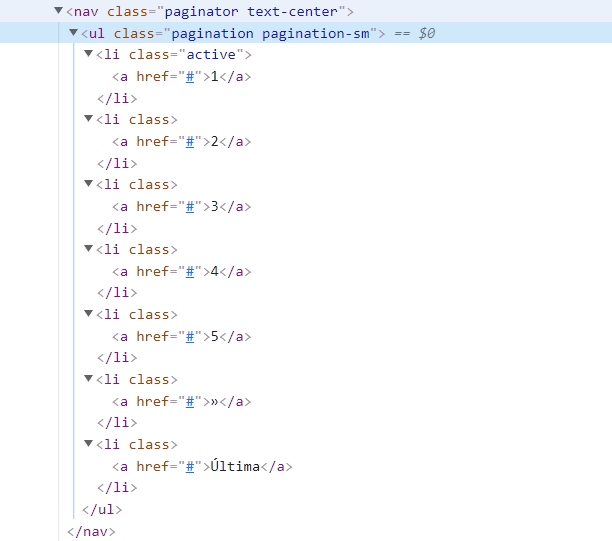
I wonder if someone can help with the code in selenium or any other library. Thanks!
CodePudding user response:
If you want to click to any element, it have to clickable (it should be somewhere on screen of web browser). That can be achieved by scrolling down the page using little JavaScript and driver.execute_script.
Working code looks like this:
import time
from selenium import webdriver
driver = webdriver.Chrome("chromedriver")
driver.get("https://salcobrand.cl/t/medicamentos")
# Scroll to bottom, so button can be clicked
driver.execute_script("window.scrollTo(0, document.body.scrollHeight - 2000);")
time.sleep(1) # Wait for page to render
# Click on element
button = driver.find_element_by_xpath("//*[@id='content']/nav/ul/li[2]/a")
button.click()
CodePudding user response:
wait=WebDriverWait(driver,0)
driver.get('https://salcobrand.cl/t/medicamentos')
while True:
try:
elem=wait.until(EC.element_to_be_clickable((By.XPATH,"//a[.='»']")))
driver.execute_script("arguments[0].scrollIntoView();",elem)
time.sleep(1)
driver.execute_script("arguments[0].click()", elem)
elem.click()
time.sleep(1)
except Exception as e:
print(str(e))
break
You can go through all 42 pages like so just by looking for that element and then clicking it.
Import:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
CodePudding user response:
In order to go through all the available pages you can click next page number until pagination button with next page will be available.
I mean starting from i = 2 you can search for button with number 2 until button with number n will be not existing.
After each click on the pagination button you will have to scrape the next page content, scroll down to the pagination button, click it and wait until the new content is loaded.
Something like this:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
import time
driver = webdriver.Chrome(executable_path='chromedriver.exe')
wait = WebDriverWait(driver, 20)
actions = ActionChains(driver)
driver.get('https://salcobrand.cl/t/medicamentos')
next_page = 2
while True:
#here scrape your data
next = driver.find_elements(By.XPATH,"//ul[@class='pagination pagination-sm']//a[@href='#' and text()=" str(next_page) "]")
if next:
actions.move_to_element(next[0]).perform()
time.sleep(0.5)
driver.find_element(By.XPATH,"//ul[@class='pagination pagination-sm']//a[@href='#' and text()=" str(next_page) "]").click()
else:
break
Indicating the new content is loaded can be done as following:
Keep some presented search result on the current page.
After clicking the next page button use Expected Condition of invisibility_of_element_located to wait for that element to disappear.