How do I find objects in one list based on objects in another list?
Here I have a .txt file with multiple sites from which I can download the necessary file by name.
If I need a single file or some specific I could download it directly by choosing the needed file, but what I have is a separate list of files that matches the download site's last characters
The list of necessary files:
print(lis)
Out[96]: ['folder1_file_1', 'folder1_file_2', 'folder1_file_3', 'folder2_file_3']
The txt file with sites which needs to be downloaded:
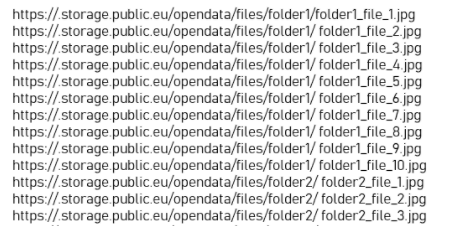
How can I find these four files in the .txt file and download them?
['folder1_file_1', 'folder1_file_2', 'folder1_file_3', 'folder2_file_3']
Here is what I have so far:
lis = ['folder1_file_1', 'folder1_file_2', 'folder1_file_3', 'folder2_file_3']
site = 'W:\storage_public_sites_all.txt'
with open(site) as f:
urllist = f.readlines()
urllist = [x.strip() for x in urllist]
for n in urllist:
b = [item for item in n if item.__contains__(lis)]
# HOW TO FIND CORRESPODNING FILES BY NAMES IN LIS
dest_folder = r'W:\download'
WORKING SOLUTION from @ljdyer:
lis = ['folder1_file_1', 'folder1_file_2', 'folder1_file_3', 'folder2_file_3']
destination = r'W:\download'
site = 'W:\storage_public_sites_all.txt'
with open(site) as f:
urllist = f.readlines()
urllist = [x.strip() for x in urllist]
files = [file for file in urllist for url in lis if url in file]
for file in files:
print(file)
import wget
wget.download(file, out=destination)
CodePudding user response:
You could get all the txt files from the list of URLs in a single list comprehension:
files = [file for file in files for url in urllist if url in file]
then you can just iterate over your list of .jpg file names to download the files:
for file in files:
...
CodePudding user response:
Try:
from urllib.parse import urlparse
from pathlib import Path
lis = ['folder1_file_1', 'folder1_file_2', 'folder1_file_3', 'folder2_file_3']
site = r'W:\storage_public_sites_all.txt'
with open(site) as f:
urldict = {Path(urlparse(line).path).stem: line.strip() for line in f}
for file in lis:
print(f"{file}: {urldict[file]}")
# do stuff here
Output:
folder1_file_1: https://storage.public.eu/opendata/files/folder1/folder1_file_1.jpg
folder1_file_2: https://storage.public.eu/opendata/files/folder1/folder1_file_2.jpg
folder1_file_3: https://storage.public.eu/opendata/files/folder1/folder1_file_3.jpg
folder2_file_3: https://storage.public.eu/opendata/files/folder2/folder2_file_3.jpg