Hi I have a dataframe that lists items that I own, along with their Selling Price.
I also have a variable that defines my current debt. Example:
import pandas as pd
current_debt = 16000
d = {
'Person' : ['John','John','John','John','John'],
'Ïtem': ['Car','Bike','Computer','Phone','TV'],
'Price':[10500,3300,2100,1100,800],
}
df = pd.DataFrame(data=d)
df
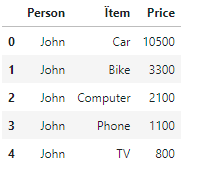
I would like to "payback" the current_debt starting with the most expensive item and continuing until the debt is paid. I would like to list the left over money aligned to the last item sold. I'm hoping the function can inlcude a groupby clause for Person as sometimes there is more than one name in the list
My expected output for the debt in the example above would be:
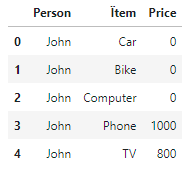
If anyone could help with a function to calculate this that would be fantastic. I wasnt sure whether I needed to convert the dataframe to a list or it could be kept as a dataframe. Thanks very much!
CodePudding user response:
Using a cumsum transformation and np.where to cover your logic for the final price column:
import numpy as np
df = df.sort_values(["Person", "Price"], ascending=False)
df['CumPrice'] = df.groupby("Person")['Price'].transform('cumsum')
df['Diff'] = df['CumPrice'] - current_debt
df['PriceLeft'] = np.where(
df['Diff'] <= 0,
0,
np.where(
df['Diff'] < df['Price'],
df['Diff'],
df['Price']
)
)
Result:
Person Item Price CumPrice Diff PriceLeft
0 John Car 10500 10500 -5500 0
1 John Bike 3300 13800 -2200 0
2 John Computer 2100 15900 -100 0
3 John Phone 1100 17000 1000 1000
4 John TV 800 17800 1800 800