I have a data frame that contain a column called DIAGNOSES. This DIAGNOSES column contain a list of 1 or multiple strings, starting with a Character.
I want to check the first character of every row in DIAGNOSES and grab its first char to look it up from a dictionary to populate DIAGNOSES_TYPE column with these values.
Minimal Example:
diagnoses = {'A': 'Arbitrary', 'B': 'Brutal', 'C': 'Cluster', 'D': 'Dropped'}
df = pd.DataFrame({'DIAGNOSES': [['A03'], ['A03', 'B23'], ['A30', 'B54', 'D65', 'C60']]})
DIAGNOSES
0 [A03]
1 [A03, B23]
2 [A30, B54, D65, C60]
A little visualization to clarify what I want to get, I want to get the df['DIAGNOSES_TYPES'] populated:
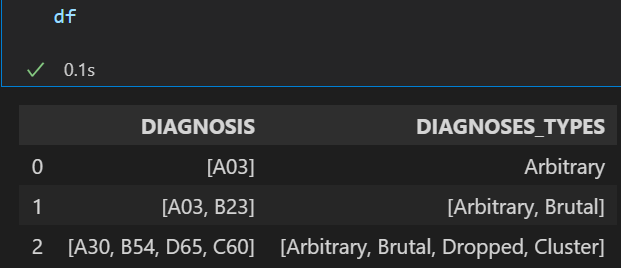
I approached it this way:
def map_diagnose(df)
for col in len(range(df)):
for d in df['DIAGNOSIS']:
for diag in d:
if diag[0] in diagnoses_dict.keys():
df['DIAGNOSES_TYPES'] = diagnoses_dict.get(diag[0])
df['DIAGNOSES_TYPES'] = ''
return df
CodePudding user response:
use explode, map and groupby:
diagnoses = {'A': 'Arbitrary', 'B': 'Brutal', 'C': 'Cluster', 'D': 'Dropped'}
df1 = df.explode('DIAGNOSES')
df1['SD'] = df1['DIAGNOSES'].str.extract('(\D)')
df1['DIAGNOSES_TYPES'] = df1['SD'].map(diagnoses)
df1.groupby(level=0).agg(list)
output:
DIAGNOSES SD DIAGNOSES_TYPES
0 [A03] [A] [Arbitrary]
1 [A03, B23] [A, B] [Arbitrary, Brutal]
2 [A30, B54, D65, C60] [A, B, D, C] [Arbitrary, Brutal, Dropped, Cluster]
Column 'SD' there is the first letter of each dagnoses used for mapping; you can drop this column if not needed
CodePudding user response:
You can explode "DIAGNOSES" column, get the first elements of each string using str, map diagnoses dictionary to get types, groupby the index and aggregate to a list:
df['DIAGNOSES_TYPE'] = df['DIAGNOSES'].explode().str[0].map(diagnoses).groupby(level=0).apply(list)
Output:
DIAGNOSES DIAGNOSES_TYPE
0 [A03] [Arbitrary]
1 [A03, B23] [Arbitrary, Brutal]
2 [A30, B54, D65, C60] [Arbitrary, Brutal, Dropped, Cluster]