Please forgive me for the poor title I did know how to ask it.
Anyways, I have the dataframe which has many stocks (in this case just GM and F), Sales growth, stock growth.
import pandas as pd
import numpy as np
d = {'year': [2000, 2000, 2001, 2001, 2002, 2002, 2003, 2003, 2004, 2004], 'Stock': ["GM", "F", "GM", "F", "GM", "F", "GM", "F", "GM", "F"], 'US Sales Growth': [.3, .3, .1, .1, .6, .6, .12, .12, .7, .7], 'Stock Growth': [.1, .2, .3, .4, .14, .16, .2, .1,.15,.16]}
df = pd.DataFrame(data=d)
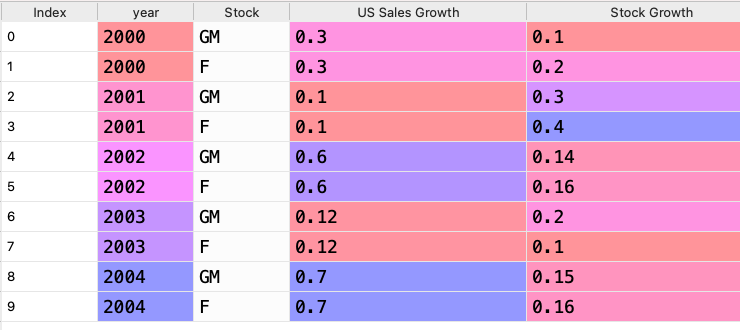
My goal is to add a column that is called "closets_sales_growth_corresponding_stock_growth" that matches the current sales growth to closes past sales growth gets its stock return to the new column. (again forgive for the poor explanation).
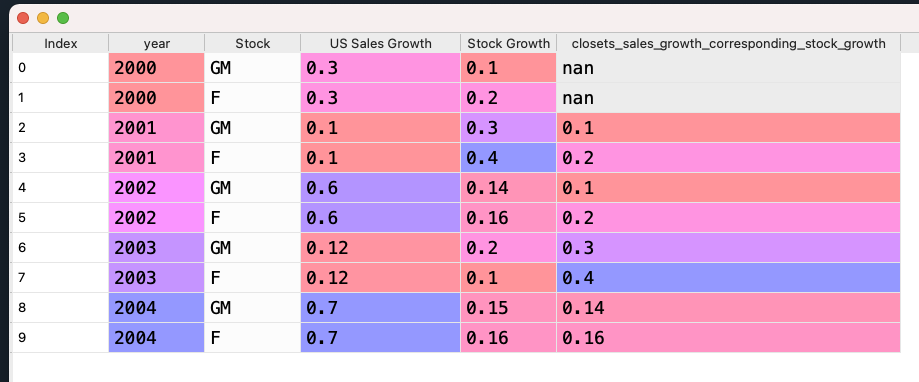
it should look like this
CodePudding user response:
I would create a function that returns the stock growth for each row. This can then be applied to each row:
import pandas as pd
import numpy as np
# Create dataframe
d = {'year': [2000, 2000, 2001, 2001, 2002, 2002, 2003, 2003, 2004, 2004], 'Stock': ["GM", "F", "GM", "F", "GM", "F", "GM", "F", "GM", "F"], 'US Sales Growth': [.3, .3, .1, .1, .6, .6, .12, .12, .7, .7], 'Stock Growth': [.1, .2, .3, .4, .14, .16, .2, .1,.15,.16]}
df = pd.DataFrame(data=d)
# Define function to find nearest value
def find_nearest_value(df, year, stock, sales_growth):
# Filter df to only include rows of same stock and earlier year
filtered_df = df[(df['year'] < year) & (df['Stock'] == stock)]
# Order the filtered row by how close they are to current sales growth
ordered = (filtered_df['US Sales Growth']-sales_growth).abs().argsort()
# Return nan if we do not find any previous value
if len(ordered) == 0:
return np.nan
stock_growth = filtered_df['Stock Growth'].iloc[(ordered[:1])].values[0]
return stock_growth
# Apply function on each row
df['closets_sales_growth_corresponding_stock_growth'] = df.apply(lambda x: find_nearest_value(df, x['year'], x['Stock'], x['US Sales Growth']), axis=1)
df
Output:
year Stock US Sales Growth Stock Growth closets_sales_growth_corresponding_stock_growth
0 2000 GM 0.30 0.10 NaN
1 2000 F 0.30 0.20 NaN
2 2001 GM 0.10 0.30 0.10
3 2001 F 0.10 0.40 0.20
4 2002 GM 0.60 0.14 0.10
5 2002 F 0.60 0.16 0.20
6 2003 GM 0.12 0.20 0.30
7 2003 F 0.12 0.10 0.40
8 2004 GM 0.70 0.15 0.14
9 2004 F 0.70 0.16 0.16
CodePudding user response:
Not pretty, but it works :)
import pandas as pd
import numpy as np
d = {'year': [2000, 2000, 2001, 2001, 2002, 2002, 2003, 2003, 2004, 2004], 'Stock': ["GM", "F", "GM", "F", "GM", "F", "GM", "F", "GM", "F"], 'US Sales Growth': [.3, .3, .1, .1, .6, .6, .12, .12, .7, .7], 'Stock Growth': [.1, .2, .3, .4, .14, .16, .2, .1,.15,.16]}
df = pd.DataFrame(data=d)
close_s_g_s = []
for i in df.index:
stock = df['Stock'][i]
cur_s_g = df['US Sales Growth'][i]
stock_growth = np.nan
min_s_g_dif = np.inf
for i_less in range(0,i):
if df['Stock'][i_less] == stock:
s_g_dif = abs(df['US Sales Growth'][i_less] - cur_s_g)
if s_g_dif < min_s_g_dif:
min_s_g_dif = s_g_dif
stock_growth = df["Stock Growth"][i_less]
close_s_g_s.append(stock_growth)
new_col = "closets_sales_growth_corresponding_stock_growth"
df[new_col] = close_s_g_s