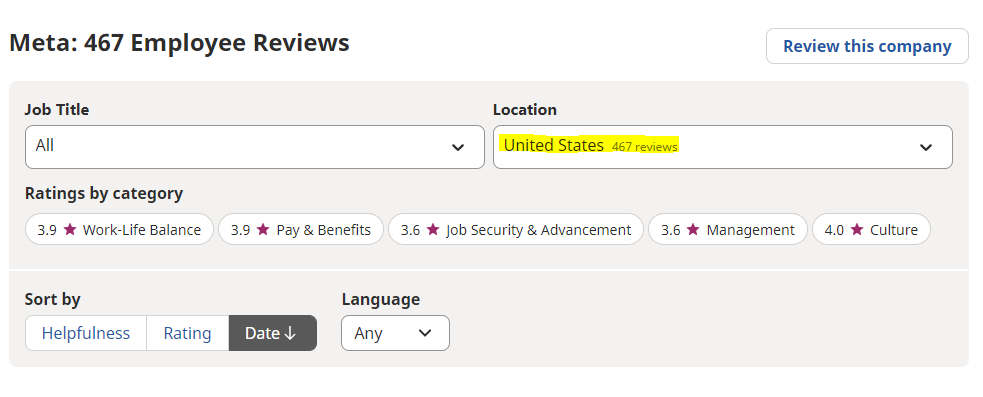
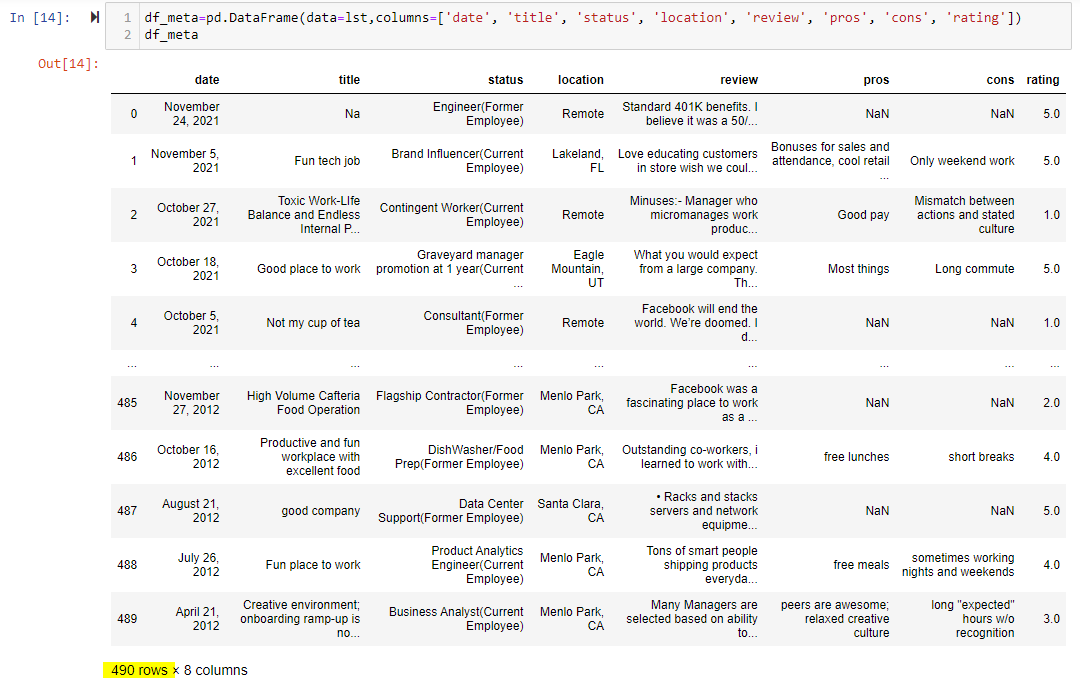
I have a question about scraping employee reviews from Indeed for Meta. I am just looking at reviews from employees in the United States, and the indeed website shows that there are 467 reviews from employees in the US as the figure shown below, but I have obtained 490 reviews from the web scrape. Why are reviews from web-scraping more than those shown on the website? How can I address this issue?
This is the link:
# Load the Modules
from bs4 import BeautifulSoup
import pandas as pd
import requests
import numpy as np
import pandas as pd
lst=[]
for i in range(0, 480, 20):
print(i)
url = (f'https://www.indeed.com/cmp/Meta-dd1502f2/reviews?start={i}')
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"}
page = requests.get(url, headers = header)
soup = BeautifulSoup(page.content, 'lxml')
main_data = soup.find_all("div",attrs={"data-tn-section":"reviews"})
for data in main_data:
try:
date=data.find("span",attrs={"itemprop":"author"}).get_text(strip=True).split("-")[2]
except AttributeError:
date=np.nan
try:
title=data.find("h2").get_text(strip=True)
except AttributeError:
title=np.nan
try:
status=data.find("span",attrs={"itemprop":"author"}).get_text(strip=True).split("-")[0]
except AttributeError:
status=np.nan
try:
location=data.find("span",attrs={"itemprop":"author"}).get_text(strip=True).split("-")[1]
except AttributeError:
location=np.nan
try:
review=data.find("span",attrs={"itemprop":"reviewBody"}).get_text(strip=True)
except AttributeError:
review=np.nan
try:
pros=data.find('h2',class_='css-6pbru9 e1tiznh50').next_sibling.get_text(strip=True)
except:
pros=np.nan
try:
cons=data.find('h2',class_='css-cvf89l e1tiznh50').next_sibling.get_text(strip=True)
except:
cons=np.nan
try:
rating=data.find("div",attrs={"itemprop":"reviewRating"}).find("button")['aria-label'].split(" ")[0]
except AttributeError:
rating=np.nan
lst.append([date, title, status, location, review, pros, cons, rating])
df_meta=pd.DataFrame(data=lst,columns=['date', 'title', 'status', 'location', 'review', 'pros', 'cons', 'rating'])
df_meta
CodePudding user response:
Indeed returns 21 results on each page. Your paging is assuming that there are 20 results on page.
However, the number of pages (24) seems to indicate there are 20 results on each page.
20 * 23 7 (on the last page) = 467
What actually happens is that each page returns 21 results:
21 * 23 7 = 490
which gives your number.
It looks like Indeed has a bug that returns incorrect number of reviews when you order by date. I did not see the same problem when ordering is based on rating.