I totally lost on this. I am using time-use data I would like to extract episodes based on time steps. So basically, individuals are asked to take 3 measurements at the same time denoted by 3 variables a_1, b_1 and c_1. In some cases, they reported the same measurement at a_2, b_2 and c_2. I would like to extract the length (the minimum length is 2) of the same measurements based on time-steps the frequency of the occurrence as well the start and end times.
For example, below the highlighted red and blue cells denote same measurement based on time-steps and not per id.

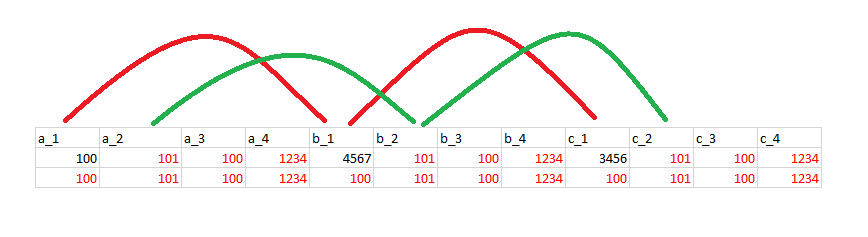
Possible output:

Sample data:
structure(list(a_1 = c(100, 100, NA), a_2 = c(101, 101, NA),
a_3 = c(100, 100, NA), a_4 = c(1234, 1234, NA), b_1 = c(4567,
100, NA), b_2 = c(101, 101, NA), b_3 = c(100, 100, NA), b_4 = c(1234,
1234, NA), c_1 = c(3456, 100, NA), c_2 = c(101, 101, NA),
c_3 = c(100, 100, NA), c_4 = c(1234, 1234, NA)), spec = structure(list(
cols = list(a_1 = structure(list(), class = c("collector_double",
"collector")), a_2 = structure(list(), class = c("collector_double",
"collector")), a_3 = structure(list(), class = c("collector_double",
"collector")), a_4 = structure(list(), class = c("collector_double",
"collector")), b_1 = structure(list(), class = c("collector_double",
"collector")), b_2 = structure(list(), class = c("collector_double",
"collector")), b_3 = structure(list(), class = c("collector_double",
"collector")), b_4 = structure(list(), class = c("collector_double",
"collector")), c_1 = structure(list(), class = c("collector_double",
"collector")), c_2 = structure(list(), class = c("collector_double",
"collector")), c_3 = structure(list(), class = c("collector_double",
"collector")), c_4 = structure(list(), class = c("collector_double",
"collector"))), default = structure(list(), class = c("collector_guess",
"collector")), delim = ","), class = "col_spec"), row.names = c(NA,
-3L), class = c("spec_tbl_df", "tbl_df", "tbl", "data.frame"))
CodePudding user response:
Using dplyr and tidyr:
library(dplyr)
library(tidyr)
df %>%
mutate(id = row_number()) %>%
gather(key, value, -id) %>%
separate(key, into = c("Msrm", "TS"), sep = "_") %>%
group_by(id, TS) %>%
filter(n_distinct(value)==1 & !is.na(value)) %>%
select(-Msrm) %>%
distinct() %>%
arrange(id) %>%
pivot_wider(id, TS) %>%
ungroup() %>%
select(sort(current_vars()), -id) %>%
mutate(Length = rowSums(!is.na(.)),
Interval = apply(., 1, function(x) paste(which(!is.na(x)), collapse = ", "))) %>%
unite("Measurement", 1:4, sep = ",", na.rm = T) %>%
group_by(across(everything())) %>%
summarize(Occurance = n())
which results to:
Measurement Length Interval Occurance
<chr> <dbl> <chr> <int>
1 101,100,1234 3 1, 2, 3 1
2 101,100,1234,100 4 1, 2, 3, 4 1
Edit: First things first we will need an id. Since we are going to mutate our data a lot you will lose sight of your ordering.
Next, we gather. This is the same as pivot_longer and melt (from reshape2 or data.table). It creates a tidy table with only 1 column of values and all of the old column names together in a new id column.
Now that we have the columnnames in a column we can easily manipulate them, so we separate them into Msrm (a, b, c) and TS (1, 2, 3, 4).
Since we want to see if for each id if all measurements are the same across a single TS we will group by id and TS. With these groups we can filter for n_distinct==1 to only keep timesteps where all values are the exact same, ignoring NA.
At this point there is no need anymore for the Msrm column so we remove it and also we remove the duplicates with the distinct function. Lastly we re-arrange the table by id.
Next we do pivot_wider to create a value column for each unique TS (1, 2, 3, 4), a bit like our original table. We also remove the id column since there is no use for it anymore at this point and sort the TS to make sure they are in the right order (1, 2, 3, 4).
At this point the table looks like this:
# A tibble: 2 x 4
`1` `2` `3` `4`
<dbl> <dbl> <dbl> <dbl>
1 NA 101 100 1234
2 100 101 100 1234
From here on we calculate the results. First we do the rowSum of a boolean (!is.na()), this essentially counts the number of columns in a row that are not equal to NA.
Then we use an apply to find the column names (which) attached to these !is.na() values. We wrap it in paste(..., collapse = ", ") to print all the column names into a single cell.
After that we can use unite to concatenate all the value columns into one while simultaneously removing the original columns. Right now it assumed that you have 4 timesteps (1:4), you could pretty easily make it dynamic if you so desire.
Lastly we group by all columns and use n() to see if any row is identical to another and count the occurrences in case they are.