I have a large dataframe a that I would like to split or explode to become dataframe b (the real dataframe a contains 90 columns).
I tried to look up for solutions to a problem similar to this but I did not find since it is not related to the values in cells but to the column names.
Any pointer to the solution or to using an existing function in the pandas library would be appreciated.
Thank you in advance.
from pandas import DataFrame
import numpy as np
# current df
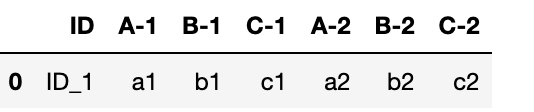
a = DataFrame([{'ID': 'ID_1', 'A-1': 'a1', 'B-1':'b1','C-1':'c1', 'A-2': 'a2', 'B-2':'b2','C-2':'c2'}])
# desired df
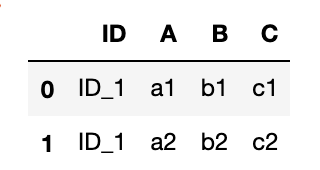
b = DataFrame([{'ID': 'ID_1', 'A': 'a1', 'B':'b1', 'C':'c1'},
{'ID': 'ID_1','A': 'a2', 'B':'b2','C':'c2'}])
current df
desired df
One idea I have is to to split this dataframe into two dataframes (Dataframe 1 will contain columns from A1 to C1 and Dataframe 2 will contain columns from A2 to C2 ) rename the columns to A/B/C and than concatenate both. But I am not sure in terms of efficiency since I have 90 Columns that will grow over time.
CodePudding user response:
This approach will generate some intermediate columns which will be removed later on.
First bring down those labels (A-1,...) from the header into a column
df = pd.melt(a, id_vars=['ID'], var_name='label')
Then split the label into character and number
df[['char', 'num']] = df['label'].str.split('-', expand=True)
Finally drop the label, set_index before unstack, and take care of the final table formats.
df.drop('label', axis=1)\
.set_index(['ID', 'num', 'char'])\
.unstack()\
.droplevel(0, axis=1)\
.reset_index()\
.drop('num', axis=1)
CodePudding user response:
