I have data-set where the bootstraps were performed such that only values within the two main factors replicate/ level were replaced.
replicate level high.density low.density
1 low 14 36
1 low 54 31
1 mid 82 10
1 mid 24 NA
2 low 12 28
2 low 11 45
2 mid 12 17
2 mid NA 24
2 up 40 10
2 up NA 5
2 up 20 2
##DATA FRAME
df <- structure(list(replicate = c(1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2), level = c("low", "low", "mid", "mid", "low", "low", "mid", "mid", "up", "up", "up"), high.density = c(14, 54, 82, 24, 12, 11, 12, NA, 40, NA, 20), low.density = c(36, 31, 10,
NA, 28, 45, 17, 24, 10, 5, 2)), class = c("spec_tbl_df","tbl_df","tbl", "data.frame"), row.names = c(NA, -11L), spec = structure(list(cols = list(replicate = structure(list(), class = c("collector_double", "collector")), level = structure(list(), class = c("collector_character","collector")), high.density = structure(list(), class = c("collector_double","collector")), low.density = structure(list(), class = c("collector_double",
"collector"))), default = structure(list(), class = c("collector_guess", "collector")), skip = 1L), class = "col_spec"))
df$replicate <- as.factor(as.numeric(df$replicate))
df$level <- as.factor(as.character(df$level))
##Creating the data-set needed for boot. Only values with-in the unique replicate/ level were allowed to shuffle (
#A sample code for the plot
df_boot <- rbindlist(df_list, idcol = 'count')
ggplot(aes(x = low.density, y = high.density), data = df_boot)
stat_smooth(aes(group = factor(count)), geom = "line", method = "lm", se = FALSE, color = "red", alpha=0.02)
stat_smooth(geom = "line", method = "lm", se = FALSE, color = "black", linetype = "longdash")
theme(panel.background = element_blank()) theme(legend.position="none")
CodePudding user response:
We may conduct a non-parametric or parametric bootstrap of the postulated linear model. The important difference between a non-parametric and a parametric bootstrap is that in the non-parametric case, we are going to repeatedly sample from our original dataframe df, whereas in the parametric case, we simulate new data from our original model.
We postulate the following linear model:
high.densityi = b0 b1low.density ei ei ~ N(0, sigma2)
It is important to first listwise delete rows containing missing observations and then run the bootstrap procedure (even though you'd better multiply impute missing observations in independents, because you will obtain biased inference if the missing data mechanism is not of the so-called MCAR type). In the 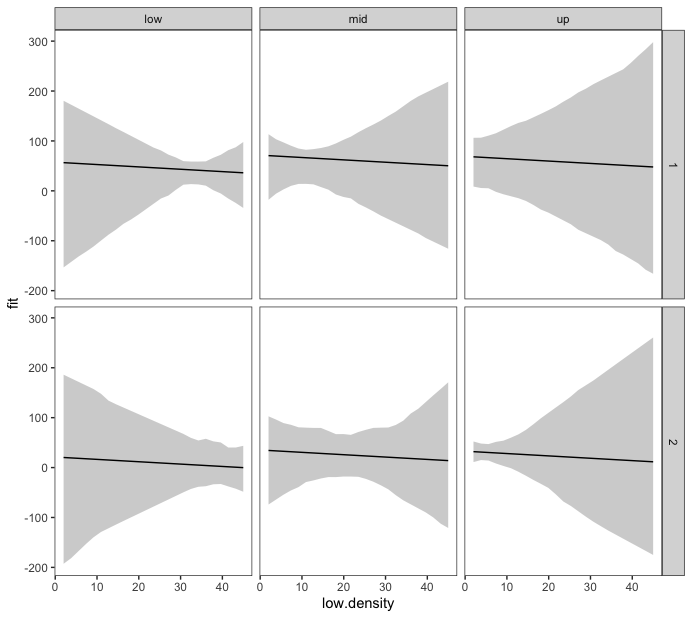
To get smoother bounds, try more bootstrap replicates.