I have a set of data points that I have used to generate my empirical CDF which looks like this (to simplify things I have reduced the number of points for this question but it shouldn't matter):
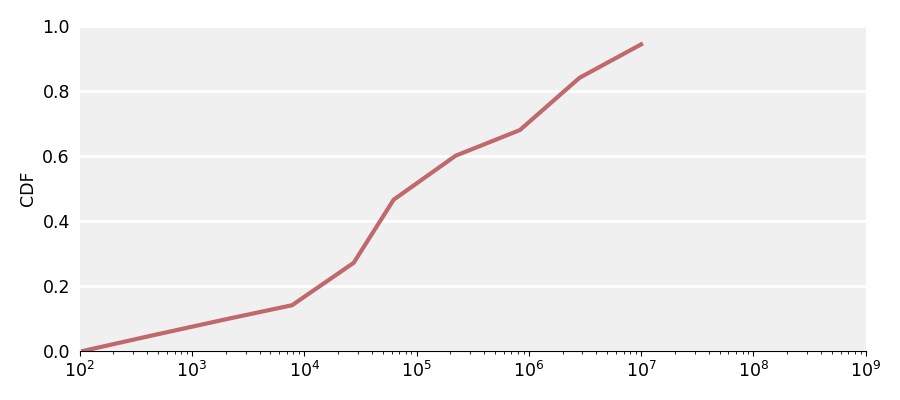
Given this data and plot I need to somehow generate random values which follow this distribution. I admit that I am quite rusty when it comes to probability, but as far as I understand I need to first generate the PDF and then from there I can do what I want. Is that accurate? Or what is the best way to get what I want?
If interested in giving an example for the answer, here are the X and Y array for the data points of the ECDF plot. I am using Python but I guess a language agnostic answer would also be really helpful
x = [107.6697676209896, 430.70331251794784, 1975.0646306785532, 7793.524079329409, 27569.66699567533, 62566.73646946178, 222847.1449910263, 832591.8949493016, 2827054.7454871265, 10000733.572934577]
y = [0, 0.04812202549318534, 0.09825964339269633, 0.14190143419466905, 0.27204351414405636, 0.46590411495145756, 0.6008552899988212, 0.6796719668120879, 0.8400864397710662, 1]
Thanks a lot!
CodePudding user response:
The standard "graphical" answer is that you pick a random number between 0.0 and 1.1, and find that on your y axis. Move right until you hit your graph. Then move down to the x axis and that's the value.
If your graph really is just an empirical graph, then the second step is a binary search through a monotonically increasingly list. The index of that found value (or the closest value) then is mapped to an x value, which is the value you want to produce.
CodePudding user response:
Just resample with replacement (aka bootstrap it) from your original sample:
draws = np.random.choice(x, size=10000, replace=True)
That's how you sample from an empirical distribution.