I am taking my first major steps into azure and just doing some research for educational purposes. There is a currently a process that exists in the business whereby files are being used and then queries are being run within the PowerBI report to provide the result.
This is causing the report to be slow naturally as its doing the calculating, I want to come up with an automated solution for this.
In my mind it would go as such:
- User (Finance Department) uploads said file to Blob Storage
- Use ADF to pull this data into a Data Lake
- Use Databricks Python Notebook to manipulate this data
- Push Data into a SQLDB or DW Solution.
Is this correct? How would I get the user (insert generic finance person here) to be able to upload the file into blob storage, at present they email it to the BI person in question, this obviously has major flaws.
Cheers
CodePudding user response:
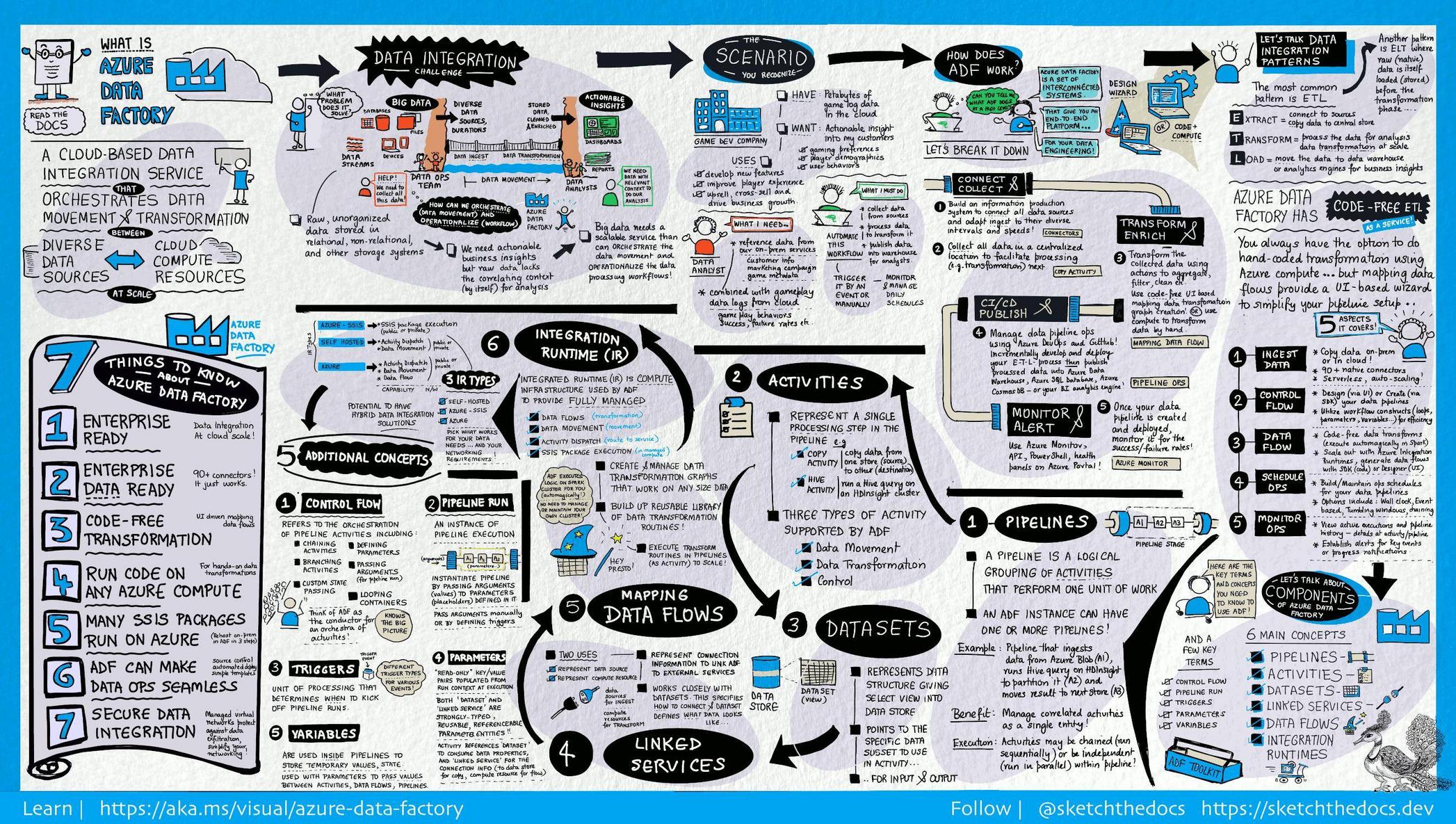
I don't know how this can help you with your end solution (PowerBI) but the flow you said it's correct. It's the flow for a ETL. Just to let you know: you can do many of data transformation and data manipulation into data factory also. So, maybe your Python Databricks it's unnecessary.
Just check the documentation and maybe this can open your mind:
CodePudding user response:
@Lynchie, your process is enormously correct.
In addition to that, you can optionally (to simplify the entire solution) replace Databricks and use Mapping Data Flow offered by Azure Data Factory itself (it is a separate activity in a pipeline), which gives you no-code capability to build transformations.
Now, in terms of your second question, probably the most convenient way for all existing users would be to keep the way of sending files via email.
Then (very easily) you can build workflow in Power Automate or Azure Logic Apps in order to intercept incoming emails (optionally filter them by subject, text in message or sender) and store all attachments as the file in target Azure Storage.