i have spend 6 hours to figure out this but i still cannot find the solution, here's the table: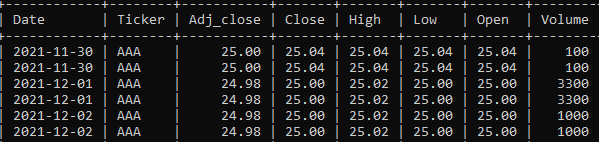
i use row_number(), CTE also cannot solve this issue. i just merely want to delete the repeated date with old data and keep the latest data, i cant keep the new data if i delete count>1 and row_number>1, please help.
i have tried below but it keeps my data all deleted:
delete from aaa where date in (select date from (select *,row_number() over (partition by date order by date) as rn from aaa)t where rn=1);
CodePudding user response:
The difficulty is that your data is completely identical. There is nothing to distinguish any other record from the next one. If you have more columns that are not displayed here, that would open up some additional options that aren't currently possible with the data set you have posted here. There are a couple options.
- Add a primary key (or at last a running index) to each row so that there is something to distinguish one entry from the next.
- Select distinct results into a temporary table. Delete everything from your existing table. And then re-insert everything from your temporary table into your existing table. Then drop your temporary table. Do your delete and insert in a single transaction so that you do not have the table temporarily empty and visible to other transactions (if we assume that your other parallel transactions will only read committed data).
If you actually have more columns, then you could group by and select the min() value from the additional column to help you distinguish them. Then you delete everthing that does not belong to this data set (your duplicate records the min(column_that_shows_a_difference).
However, you really should add a primary key to your table (even if it is simply a auto-generated identity column that isn't reflected in your application data model). When you have a business key that tells you something is (or ought to be) unique, then you should additionally create a unique-constraint.
CodePudding user response:
You could try using a delete with join based on subqoery for not matching max date
delete aaa
from aaa
inner join (
select aaa.ticker, date
from aaa
left join (
select aaa.ticker, max(date) as max_date
from aaa
group by ticker
) t on aaa.ticker = t.ticker and aaa.date = t.max_date
where t.max_date is null
) t2 on t2.ticker = aaa.ticker
and t2.date = aaa.date
CodePudding user response:
I think that's the only solution with adding primary key for auto increment with below code executed:
delete t1
from aaa t1
inner join aaa t2
where t1.id < t2.id and t1.date = t2.date;