import pandas as pd
raw_data = {'FirstName': ["John", "Jill", "Jack", "John", "Jill", "Jack",],
'LastName': ["Blue", "Green", "Yellow","Blue", "Green", "Yellow"],
'Building': ["Building1", "Building1", "Building2","Building1", "Building1", "Building2"],
'Month': ["November", "November", "November", "December","December", "December"],
'Sales': [100, 150, 275, 200, 150, 150]}
frame = pd.DataFrame(raw_data, columns =raw_data.keys())
df = frame.pivot(
index=["FirstName", "LastName", "Building"],
columns="Month",
values="Sales",
)
df
I have some simple code here that generates a multi-level index dataframe that looks like this:
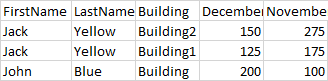
But, I was wondering if it's possible to merge, just visually rows in 1 column, like so:
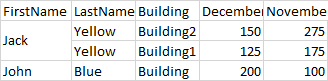
So you can see here, that instead of "Jack" showing up in 2 rows, now there's just 1 merged cell. Indexing does something like this automatically, but if I remove indexing I'd like to mimic this feature, is that possible?
CodePudding user response:
Try:
df = frame.pivot(
index=["FirstName", "LastName", "Building"],
columns="Month",
values="Sales",
).rename_axis(columns=None).reset_index()
Output:
>>> df
FirstName LastName Building December November
0 Jack Yellow Building2 150 275
1 Jill Green Building1 150 150
2 John Blue Building1 200 100
Update
Suppose the following dataframe:
>>> df
FirstName LastName Building December November
0 Jack Yellow Building2 150 275
1 Jack Yellow Building1 125 175
2 John Blue Building 200 100
You can do something like this:
df.loc[df['FirstName'].eq(df['FirstName'].shift()), 'FirstName'] = ''
print(df)
# Output
FirstName LastName Building December November
0 Jack Yellow Building2 150 275
1 Yellow Building1 125 175
2 John Blue Building 200 100
I checked if the first name of current row is the same than the previous one. If yes, I replace the first name by ''. So when (index 1, Jack) == (index 0, Jack), I set (index 1, Jack) to ''