I'm using spark sql on Databricks to do data analysis, and I wand to format some fields, but it is a bit tricky.
I have two fields, perfume and brand, what I want is, to remove the brand name only from the end of the perfume column.
Here's an example:
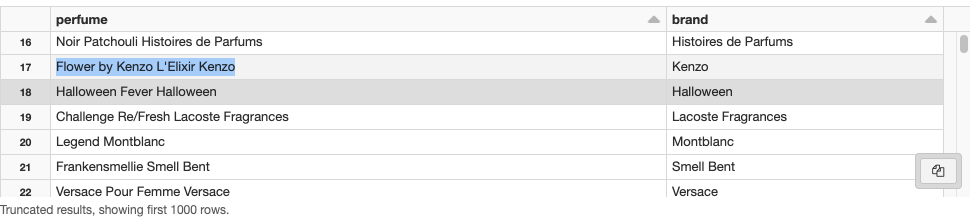
I have tried this :
SELECT substring_index(perfume,brand,1),brand FROM global_temp.gv_web
This approach works just with some fields but in some cases it removes all the name from the perfume field like this example :
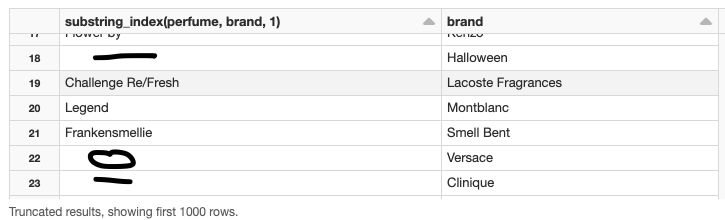
The removed fields are :
Halloween Fever Halloween
Versace Pour Femme Versace
Clinique Happy Summer Spray 2009 Clinique
How can I fix this problem please?
CodePudding user response:
You can use regexp_replace function with this regex:
(\s*BRAND\s*)*$ # removes all brand names that comes at the end
For cases where perfume name is the same as brand name then the output of regexp_replace will be empty string, using when expression you can check if it's empty then use brand name:
SELECT CASE WHEN trim(regexp_replace(perfume, format_string('(\\s*%s\\s*)*$', brand), '')) <> ''
THEN regexp_replace(perfume, format_string('(\\s*%s\\s*)*$', brand), '')
ELSE brand
END AS perfume,
brand
FROM global_temp.gv_web