I have a series of hdf5 files holding large panda data frames. a typical file is around 1000,000 rows. I use complib='blosc',complevel=9 for compression. original hdf5 files are saved as 1 flat file.
I then tried segmenting the dataframes logically to 30 smaller dataframes and saved them in the same hdf5 file with 30 different keys and the same compression.
The shocking issue is that the files with 30 smaller dataframes are 40X larger than the flat file.
flat hdf5 file is saved as follows:
dfx.to_hdf(file_name, key='opp',mode='a',complib='blosc',complevel=9, append=True)
segemented hdf5 file is saved as follows:
for i in range(30): dfx_small[i].to_hdf(file_name,key='d' str(i), mode='a',complib='blosc',complevel=9
Am I doing something wrong or is this size increase expected?
Additonal Observation
I compared all the hdf5 files generated as 1)flat dataframe vs 2)30 chunk dataframe - It seems largest files gain 8x to 10x in size when dataframe is saved as 30 smaller dataframe, meanwhile smaller files gain 100x to 1000x in size. I then experimented with saving the hdf5 files with 30 chunks with and without compression. It seems that when multiple dataframe with unique keys are placed in the same hdf5 file, the compression is almost non functional. I've tried all compression options with similar results.
There is a bug with compression when saving hdf5 files with multiple datasets.
CodePudding user response:
I created some simple tests, and discovered some interesting behavior.
- First, I created some data to mimic your description and saw a 11x increase in file size going from 1 DF to 30 DFs. So, clearly something's going on...(You will have to provide come code that replicates the 40x increase.)
- Next using the same dataframes above I created 2 uncompressed files -- I did not include the compression parameters:
complib='blosc',complevel=9. As expected, the uncompressed files were larger, but the increase from 1 DF to 30 DFs was much lower (only 65% increase).
Pandas Results
| # of DFs | Compression | Size (MB) |
|---|---|---|
| 1 | Blosc-9 | 3.1 |
| 30 | Blosc-9 | 33.5 |
| 1 | No | 24.8 |
| 30 | No | 54.8 |
So, some of this behavior could be due to compression differences with multiple, smaller dataframes. (Likely compression isn't as effective.) Also, Pandas uses an "interesting" schema to store dataframes. If you inspect the files with HDF View, the data does not look like a table (like you would see if you used PyTables or h5py to save the data). There may be overhead that is duplicated when you have multiple dataframes (but that is just an inference).
Updated 2021-01-08:
You can also save to HDF5 format using PyTables or h5py. (Pandas is built on top of PyTables.) Out of curiosity, I extended my example above to write HDF5 files with each package. One file has a single dataset and the other has 30 datasets (to mimic the dataframes method). I also compared effect of compression. Results provide interesting insights.
PyTables Results
| # of DSs | Compression | Size (MB) |
|---|---|---|
| 1 | Blosc-9 | 0.14 |
| 30 | Blosc-9 | 0.40 |
| 1 | Zlib-9 | 0.08 |
| 30 | Zlib-9 | 0.17 |
| 1 | No | 11.9 |
| 30 | No | 13.5 |
Pandas vs PyTables Observations
- In all cases, the file written with PyTables is much smaller than the corresponding file from Pandas.
- For files written with PyTables, the number of datasets has a smaller affect on the file size.
- The effect of compression going from 1->30 datasets with PyTables is less significant than Pandas (with either compression library).
- Compression is much more effective with PyTables vs Pandas (as a percentage reduction).
- Conclusion: PyTables compression and HDF5 technology works well and is not the source of your problem.
h5py Results
| # of DSs | Compression | Size (MB) |
|---|---|---|
| 1 | Gzip-9 | 0.15 |
| 30 | Gzip-9 | 0.40 |
| 1 | No | 11.9 |
| 30 | No | 11.9 |
Pandas vs h5py Observations
- In 3 out of 4 cases, the file written with h5py is much smaller than the corresponding file from Pandas. The only Pandas file that is smaller is the compressed file with 1 DF.
- For files written with h5py, the number of datasets does not affect file size.
- The effect of compression going from 1->30 datasets with h5py is insignificant (using gzip library).
- Compression is much more effective with h5py (as a percentage reduction).
PyTables vs h5py Observations
- In most cases, the file written with PyTables is very similar in size as the corresponding file from h5py. The only h5py file that is smaller is the uncompressed file with 30 datasets.
- For uncompressed files written with h5py, the number of datasets does not affect file size.
- For uncompressed files written with Pytables, increasing the number of datasets increases the file size (by 14% with this test data).
Create test data (as lists):
import string
col1 = list(string.ascii_letters)
col2 = [ x for x in range(1,53)]
col3 = [ float(x) for x in range(1,53)]
ncopies = 18_000
nslices = 30
fact = len(col1)*ncopies//nslices
col_c = []; col_int = []; col_float = []
for i in range(ncopies):
col_c.extend(col1)
col_int.extend(col2)
col_float.extend(col3)
Write test data with Pandas:
import pandas as pd
dfx = pd.DataFrame({'col_c': col_c, 'col_int': col_int, 'col_float': col_float})
dfx.to_hdf('pd_file_1_blosc.h5',key='test_data',mode='a',complib='blosc',complevel=9)
dfx.to_hdf('pd_file_1_uc.h5',key='test_data',mode='a')
for i in range(nslices):
dfx_small = dfx[i*fact:(i 1)*fact]
dfx_small.to_hdf('pd_file_30_blosc.h5',key=f'd{i:02}', mode='a',complib='blosc',complevel=9)
dfx_small.to_hdf('pd_file_30_uc.h5',key=f'd{i:02}', mode='a')
Create NumPy recarray for PyTables and h5py:
import numpy as np
arr_dt = np.dtype([ ('col_c', 'S1'), ('col_int', int), ('col_float', float) ])
recarr = np.empty(shape=(len(col_c),), dtype=arr_dt)
recarr['col_c'] = col_c
recarr['col_int'] = col_int
recarr['col_float'] = col_float
Write test data with PyTables:
import tables as tb
f_blosc = tb.Filters(complib ="blosc", complevel=9)
f_zlib = tb.Filters(complib ="zlib", complevel=9)
with tb.File('tb_file_1_blosc.h5','w') as h5f:
h5f.create_table('/','test_data', obj=recarr, filters=f_blosc)
with tb.File('tb_file_1_zlib.h5','w') as h5f:
h5f.create_table('/','test_data', obj=recarr, filters=f_zlib)
with tb.File('tb_file_1_uc.h5','w') as h5f:
h5f.create_table('/','test_data', obj=recarr)
with tb.File('tb_file_30_blosc.h5','w') as h5f:
for i in range(nslices):
h5f.create_table('/',f'test_data_{i:02}', obj=recarr[i*fact:(i 1)*fact],
filters=f_blosc)
with tb.File('tb_file_30_zlib.h5','w') as h5f:
for i in range(nslices):
h5f.create_table('/',f'test_data_{i:02}', obj=recarr[i*fact:(i 1)*fact],
filters=f_zlib)
with tb.File('tb_file_30_uc.h5','w') as h5f:
for i in range(nslices):
h5f.create_table('/',f'test_data_{i:02}', obj=recarr[i*fact:(i 1)*fact])
Write test data with h5py:
import h5py
with h5py.File('h5py_file_1_gzip.h5','w') as h5f:
h5f.create_dataset('test_data', data=recarr, compression="gzip", compression_opts=9)
with h5py.File('h5py_file_1_uc.h5','w') as h5f:
h5f.create_dataset('test_data', data=recarr)
with h5py.File('h5py_file_30_gzip.h5','w') as h5f:
for i in range(nslices):
h5f.create_dataset(f'test_data_{i:02}', data=recarr[i*fact:(i 1)*fact],
compression="gzip", compression_opts=9)
with h5py.File('h5py_file_30_uc.h5','w') as h5f:
for i in range(nslices):
h5f.create_dataset(f'test_data_{i:02}', data=recarr[i*fact:(i 1)*fact])
CodePudding user response:
My previous answer compare file sizes created by Pandas, PyTables and h5py based on compression and number of dataframes . There is another option to consider when writing from Pandas: format=. The default is format='fixed' with an option to use format='table'. Pandas docs says this about the 2 formats:
'fixed': Fixed format. Fast writing/reading. Not-appendable, nor searchable.
'table': Table format. Write as a PyTables Table structure which may perform worse but allow more flexible operations like searching / selecting subsets of the data.
Pandas tests in my previous answer were all run with the default ('fixed'). I ran additional tests to compare file sizes between 'fixed' and 'table'. Results are promising if you don't require the fixed format. File sizes for table format approach those created when writing directly from PyTables (not surprising).
Pandas Results: Fixed vs Table Format
| # of DFs | Compression | Fixed - Size (MB) | Table - Size (MB) |
|---|---|---|---|
| 1 | Blosc-9 | 3.1 | 0.72 |
| 30 | Blosc-9 | 33.5 | 1.2 |
| 1 | Zlib-9 | 0.64 | |
| 30 | Zlib-9 | 1.1 | |
| 1 | No | 24.8 | 23.4 |
| 30 | No | 54.8 | 23.9 |
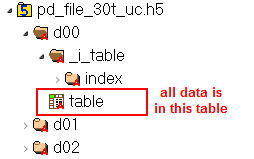
Likely this is a result of the different schemas used by fixed vs table formats. The fixed format puts data in several datasets for each key. In contrast, the tables format only creates a single table of data. (Images showing comparison below.) This isn't significant when there is only one key. However, compression is done at the dataset level, so there are a lot more small objects when fixed is used, reducing the effectiveness of compressing them.
Fixed Format Schema
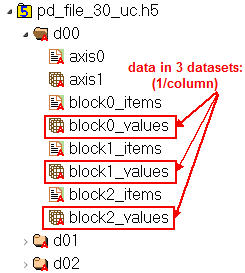
Table Format Schema