import pandas as pd
df = pd.read_csv('coords.csv',sep=',',header=1)
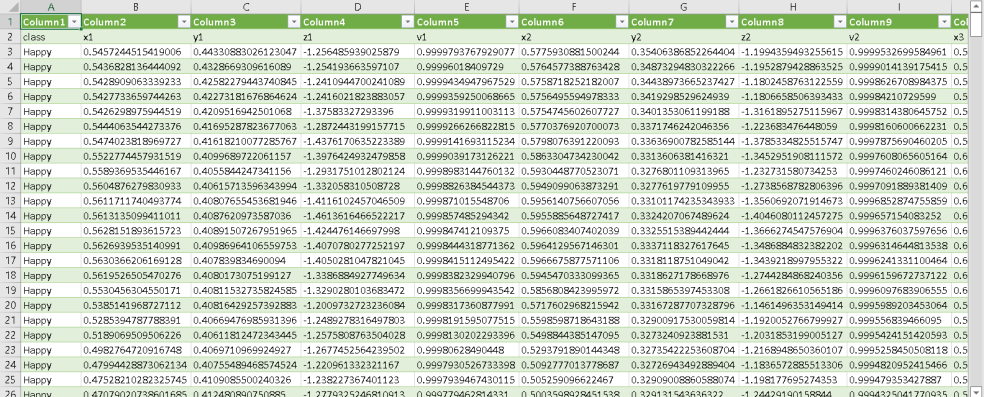
In this case, the header row that has the word "class" in its first column is repeated a few rows below, and what I need is to leave the csv file with only the first row that contains the word "class" in its first column and the rest remove them. When I mean to remove them, I do not mean that they are left blank because that would affect the data, but simply remove them
CodePudding user response:
Here's a little script to filter out those rows. It doesn't load the whole file into memory, instead doing a read-write for every row, except rows that start with 'class':
import csv
with open('coords_filtered.csv', 'w', newline='') as out_f:
writer = csv.writer(out_f)
with open('coords.csv', newline='') as in_f:
reader = csv.reader(in_f)
# Transfer header
writer.writerow(next(reader))
for row in reader:
if row[0] == 'class':
continue # skip row / don't write
writer.writerow(row)
CodePudding user response:
If I understood right you need to purge all the repeated headers appearing within data. If that's the case and the file is not that huge you can filter the dataframe after the read_csv using
import pandas as pd
df = pd.read_csv('coords.csv',sep=',',header=0)
df = df[df['class'] != 'class']
Edit: To make it working you must treat the first row, which has index 0 as an header so the dataframe can be filtered