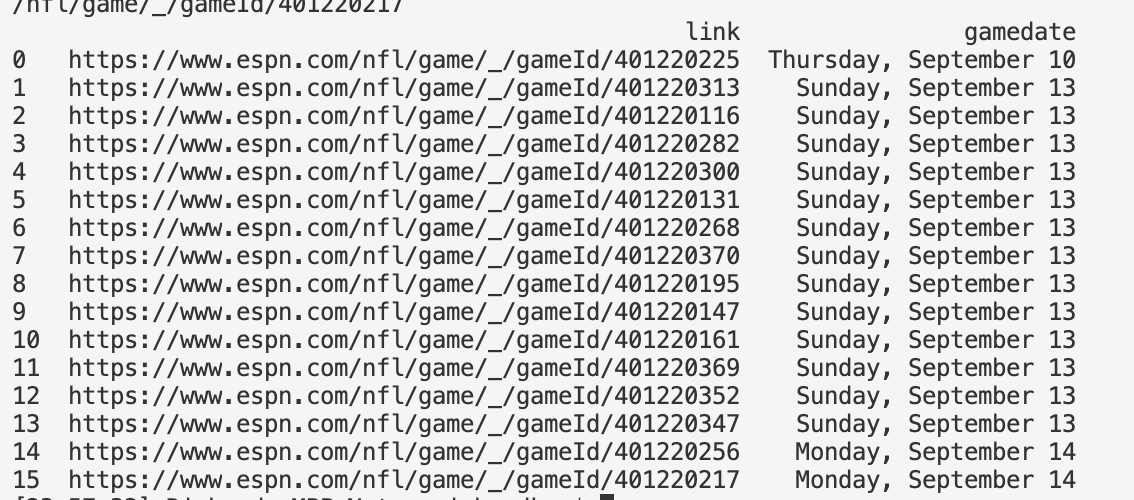
The code below finds all the links with gameId and puts the links in a dataframe. My issue is that I am not sure how I store them in a dataframe with the corresponding date. In this case the h2 is the parent tag with the child tag having the links. The code below get the links but how get date for each gameId.
import pandas as pd
import requests
from bs4 import BeautifulSoup
gmdf = pd.DataFrame(columns=['link','gamedate'])
url = 'https://www.espn.com/nfl/schedule/_/week/1/year/2020'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.select('a')
for link in links:
if 'gameId' in link.get('href'):
print(link.get('href'))
hlink = 'https://www.espn.com' link.get('href')
gmdf = gmdf.append({'link': hlink}, ignore_index=True)
This line to get the dates on the page but I need the dates with corresponding gameid in the data frame.
soup.select('h2')
CodePudding user response:
You can grab parent and siblings of elements just like in JavaScript.
Replace this after links = soup.select('a'),
schedule_year = soup.select_one('.automated-header h1').text.split("- ")[-1] # For the schedule year
for link in links:
if 'gameId' in link.get('href'):
schedule_date = link.parent.parent.parent.parent.parent.previous_sibling.text.split(", ")[-1] " " schedule_year # Grabs the h2 tag
schedule_date = datetime.datetime.strptime(schedule_date, "%B %d %Y") # Converted the date to datetime object for manipulation
hlink = 'https://www.espn.com' link.get('href')
gmdf = gmdf.append({'link': hlink, 'gamedate': schedule_date}, ignore_index=True)
Hope this solves it. Happy coding!
CodePudding user response:
Here is an alternative method from what Dhivakar has already provided. In it, I add the h2 tag in the original selection by BeautifulSoup, then, I set the date based on when the link does not have an href, since we know it must either be h2 or a tag, and h2 tags contain the dates.
import pandas as pd
import requests
from bs4 import BeautifulSoup
gmdf = pd.DataFrame(columns=['link','gamedate'])
url = 'https://www.espn.com/nfl/schedule/_/week/1/year/2020'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.select('a, h2')
date = ""
for link in links:
if link.get('href') is None:
date = link.text
print(date)
elif link.get('href') is not None and 'gameId' in link.get('href'):
print(date)
print(link.get('href'))
hlink = 'https://www.espn.com' link.get('href')
gmdf = gmdf.append({'link': hlink, 'gamedate': date}, ignore_index=True)
print(gmdf)
Output: