A is my reference data-frame. It will always have only one row.
A = pd.DataFrame({'a': [5], 'b': [3], 'c': ['C'], 'd' : ['D'], 'e' : ['E'], 'f' : [True], 'g' : [7]})
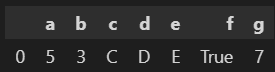
I want to use above data frame to replace NA and append missing columns in the below data frame. The index of A is ignored.
x = pd.DataFrame({'a': [1,2,3,4], 'b': [0,1,np.nan, 1], 'e': ['Ex1', np.nan, 'Ex2', np.nan]})
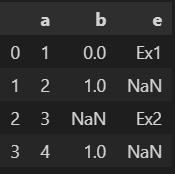
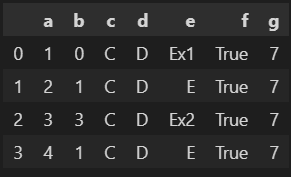
The expected result is shown below.
Language - Python, Library pandas
CodePudding user response:
You can reindex using the columns of A and then .fillna using the first (and only) row (as a Series) so that the filling aligns on the column labels.
Let pandas 'infer' the downcasting so that the rows that can be cast to int64 don't remain as float64, if that's important.
x = x.reindex(A.columns, axis=1).fillna(A.iloc[0], downcast='infer')
a b c d e f g
0 1 0 C D Ex1 True 7
1 2 1 C D E True 7
2 3 3 C D Ex2 True 7
3 4 1 C D E True 7