I have a dataset like this:
ID color_1 color_2 shape_1 shape_2 size class
55 red blue circle triangle small A
83 blue yellow circle NA large B
78 red yellow square circle large B
43 green NA square circle small C
29 yellow green circle triangle medium A
Before I asked a question about how to make a frequency table of my data and received this answer:
pat_words <- c("color", "shape", "size")
out <- df %>%
pivot_longer(
-ID,
names_to = "Question",
values_to = "Response"
) %>% mutate(Question = str_extract(Question, str_c(pat_words, collapse="|"))) %>% group_by(Question, Response) %>%
count(Response, name = "Freq") %>%
na.omit() %>%
group_by(Question) %>%
mutate(Percent = round(Freq/sum(Freq)*100, 2)) %>%
group_split() %>%
adorn_totals() %>%
bind_rows() %>%
mutate(Response = ifelse(Response == last(Response), last(Question), Response)) %>%
mutate(Question = ifelse(duplicated(Question) |
Question == "Total", NA, Question)) %>%
as.data.frame
And was able to get the following output:
Variable Level Freq Percent
color blue 2 22.22
red 2 22.22
yellow 3 33.33
green 2 22.22
total 9 100.00
shape circle 5 50.0
triangle 3 30.0
square 2 20.0
total 10 100.0
size small 2 33.3
medium 2 33.3
large 2 33.3
total 6 100.0
However now I want to group by a new variable "class":
Class A B C
Variable Level Freq Percent Freq Percent Freq Percent
color blue 1 25 1 25 0 0
red 1 25 1 25 0 0
yellow 1 25 2 50 0 0
green 1 25 0 0 1 100
total 4 100.00 4 100.00 1 100
shape circle 2 50 2 66.7 1 50
triangle 2 50 0 0 0 0
square 0 0 1 33.3 1 50
total 4 100.0 3 100.0 2 100
size small 1 50 0 0 1 100
medium 1 50 0 0 0 0
large 0 0 2 100 0 0
total 2 100.0 2 100 1 100
I have tried to just add class to the group by statement and I am getting an error. Any help is greatly appreciated!
CodePudding user response:
We can modify the OP's code in the grouping i.e. grouped by 'class, 'Variable', calculate the 'Percent', and create the 'Total' row with adorn_totals before reshaping back to 'wide' with pivot_wider
library(dplyr)
library(tidyr)
library(janitor)
library(stringr)
out <- df %>%
pivot_longer(cols = -c(ID, class), names_to = 'Variable',
values_to = 'Level', values_drop_na = TRUE) %>%
mutate(Variable = str_remove(Variable, "_\\d ")) %>%
count(class, Variable, Level, name = "Freq") %>%
group_by(class, Variable) %>%
mutate(Percent = round(100 * Freq/sum(Freq))) %>%
group_modify(~ .x %>%
adorn_totals()) %>%
ungroup %>%
pivot_wider(names_from = class, values_from = c(Freq, Percent),
values_fill = 0) %>%
select(Variable, Level, ends_with('A'), ends_with('B'), ends_with('C')) %>%
arrange(Variable)
-output
out
# A tibble: 13 × 8
Variable Level Freq_A Percent_A Freq_B Percent_B Freq_C Percent_C
<chr> <chr> <int> <dbl> <int> <dbl> <int> <dbl>
1 color blue 1 25 1 25 0 0
2 color green 1 25 0 0 1 100
3 color red 1 25 1 25 0 0
4 color yellow 1 25 2 50 0 0
5 color Total 4 100 4 100 1 100
6 shape circle 2 50 2 67 1 50
7 shape triangle 2 50 0 0 0 0
8 shape Total 4 100 3 100 2 100
9 shape square 0 0 1 33 1 50
10 size medium 1 50 0 0 0 0
11 size small 1 50 0 0 1 100
12 size Total 2 100 2 100 1 100
13 size large 0 0 2 100 0 0
The above output can be converted to a flextable
library(flextable)
out %>%
mutate(Variable = replace(Variable, duplicated(Variable), NA)) %>%
flextable()
-output
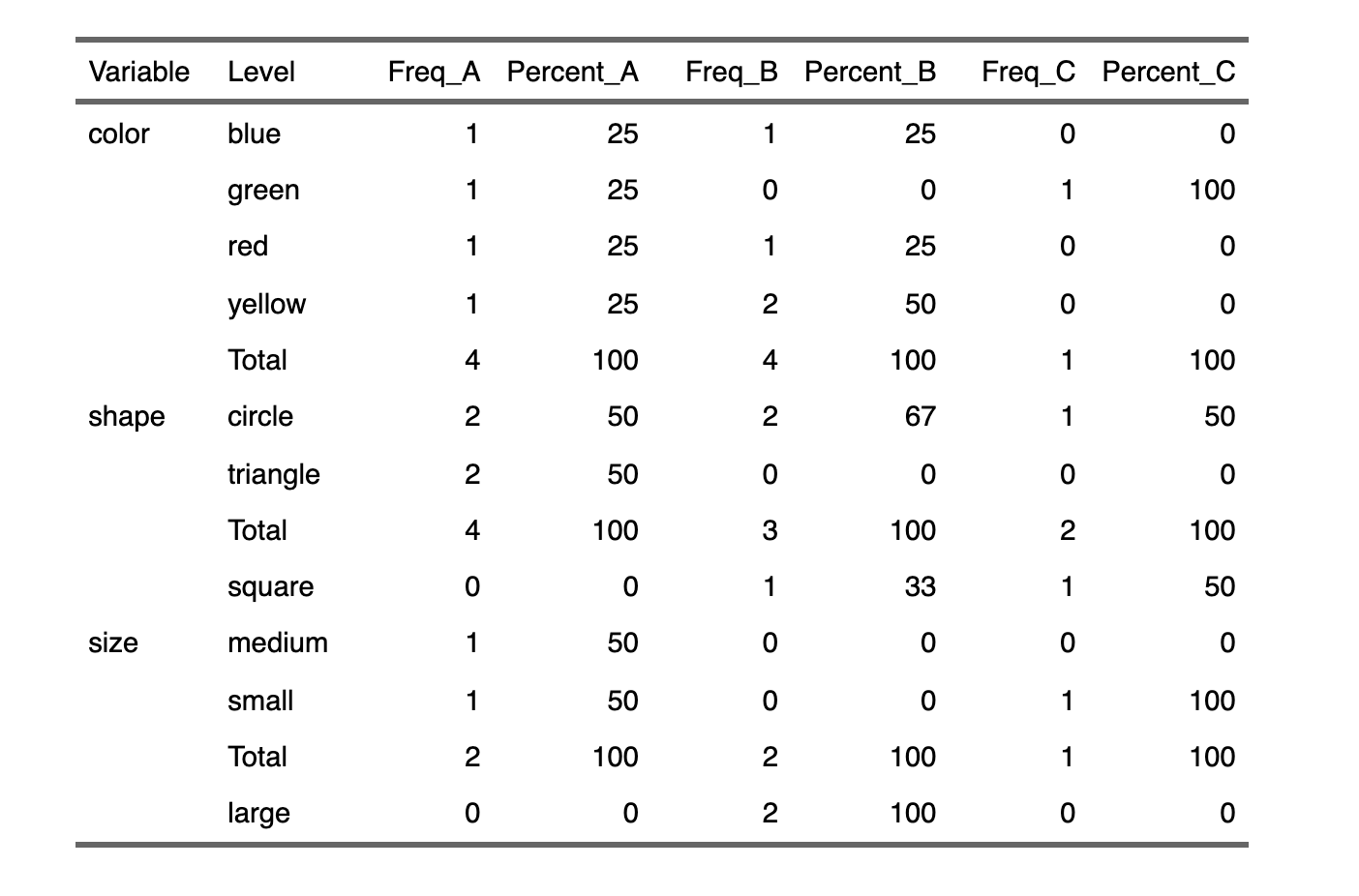
data
df <- structure(list(ID = c(55L, 83L, 78L, 43L, 29L), color_1 = c("red",
"blue", "red", "green", "yellow"), color_2 = c("blue", "yellow",
"yellow", NA, "green"), shape_1 = c("circle", "circle", "square",
"square", "circle"), shape_2 = c("triangle", NA, "circle", "circle",
"triangle"), size = c("small", "large", "large", "small", "medium"
), class = c("A", "B", "B", "C", "A")), class = "data.frame", row.names = c(NA,
-5L))
CodePudding user response:
You could use the 
CodePudding user response:
Another possible solution, based on purrr::reduce and dplyr::full_join:
library(tidyverse)
df %>%
pivot_longer(cols = !contains(c("ID", "class")), names_to = "Variable",
values_to = "Level", values_drop_na = T) %>%
add_count(class, Variable = str_remove(Variable,"_\\d$")) %>%
group_by(class, Variable, Level) %>%
summarise(count = n(), perc = 100*count/n, .groups = "drop") %>%
group_split(class) %>%
reduce(full_join, by=c("Variable", "Level"), suffix=c(".A",".B")) %>%
select(-starts_with("class")) %>% distinct %>%
arrange(Variable) %>%
rename("count.C" = "count", "perc.C" = "perc") %>%
mutate(across(contains("."), ~ replace_na(.x,0)))
#> # A tibble: 10 × 8
#> Variable Level count.A perc.A count.B perc.B count.C perc.C
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 color blue 1 25 1 25 0 0
#> 2 color green 1 25 0 0 1 100
#> 3 color red 1 25 1 25 0 0
#> 4 color yellow 1 25 2 50 0 0
#> 5 shape circle 2 50 2 66.7 1 50
#> 6 shape triangle 2 50 0 0 0 0
#> 7 shape square 0 0 1 33.3 1 50
#> 8 size medium 1 50 0 0 0 0
#> 9 size small 1 50 0 0 1 100
#> 10 size large 0 0 2 100 0 0