I have a CSV dataset for an ML classifier. It has 2 columns and looks like this:

But this dataset is very dirty, so I decided to open it with Excel, remove "dirty" words, and save it as a new CSV file and train my ML classifier on it.
But after I saved it in Excel (using , separator and also tried , UTF-8), and when trying pd.read_csv on it, it gives me this error:
Error tokenizing data. C error: Expected 3 fields in line 4, saw 5
Then I tried to use sep=';' with read_csv, and it worked, but now all Russian characters are replaced with strange symbols:
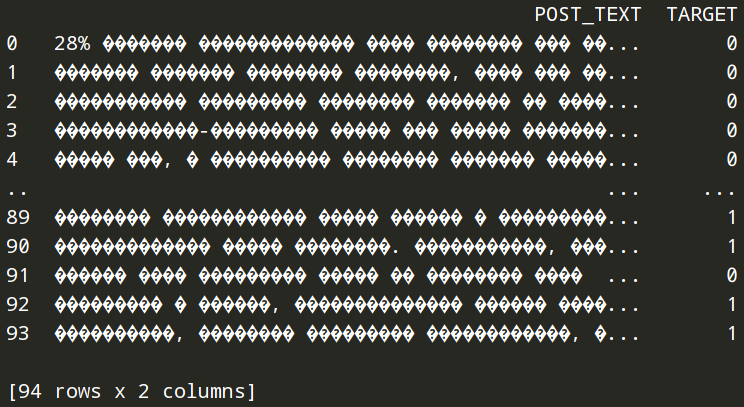
Can somebody explain please how to repair "question"-symbols from Russian characters? encoding='UTF-8' gives this error:
'utf-8' codec can't decode byte 0xe6 in position 22: invalid continuation byte
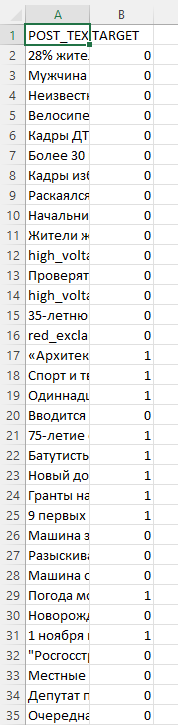
This is what the first file looks like (not modified Excel .csv file):

When I open second file (modified):
CodePudding user response:
Try opening the file with either ptcp154 or kz1048 encodings. They seem to work.