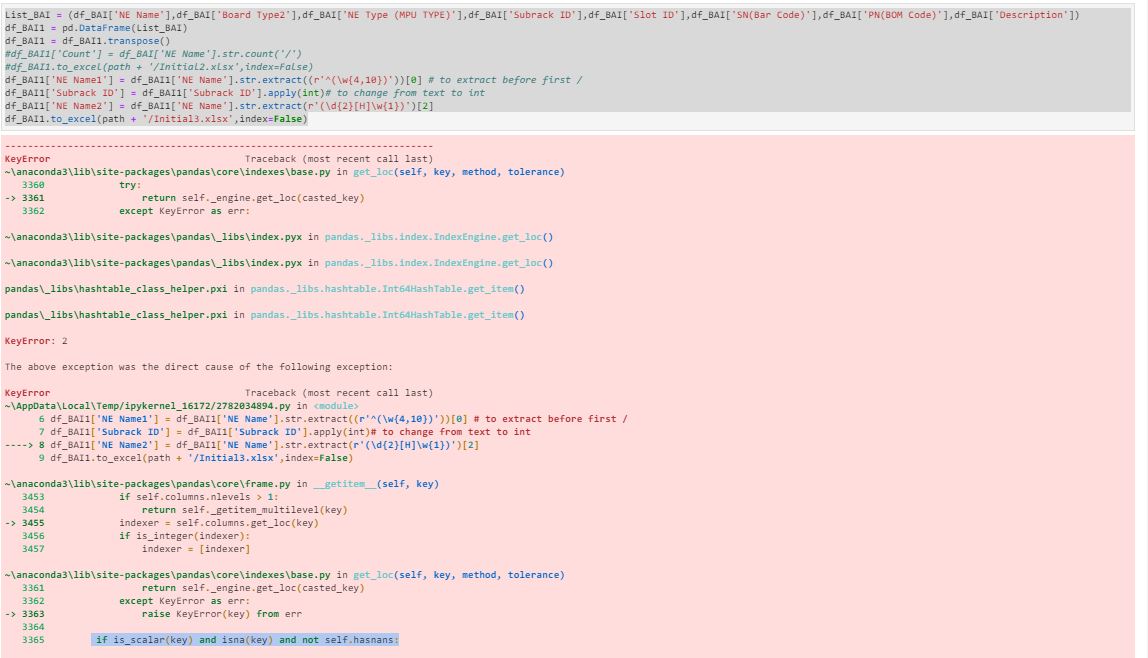
I am trying to extract 4 characters after First,second,third and so on occurance of '/' from Column of Dataframe
Can someone suggest possible code let me know what is error in my code
CodePudding user response:
Try with str.findall:
>>> df["NE Name"].str.findall(r"/([^/]{4})")
0 [01HJ]
1 [01HL, 02HL, 03HL, 10HL]
2 [01HL, 02HL, 03HL, 10HL]
3 [01HL, 02HL, 03HL, 10HL]
4 [01HL, 02HL, 03HL, 10HL]
Name: NE Name, dtype: object
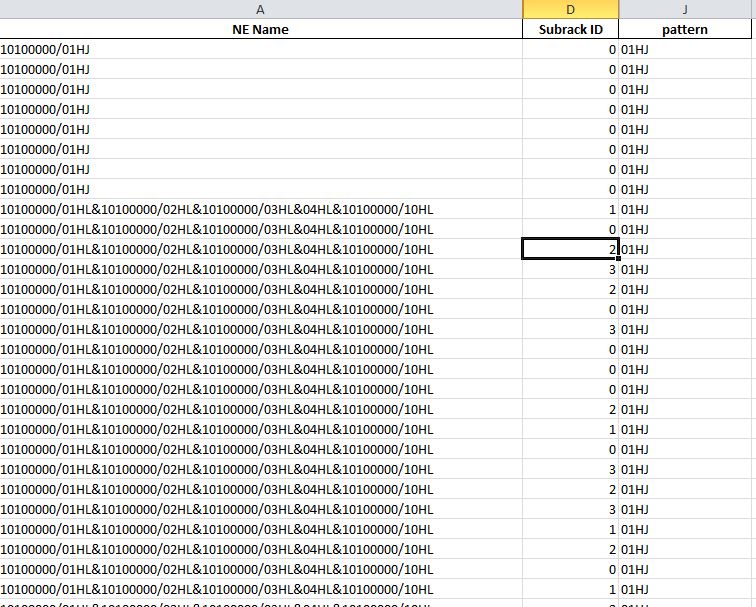
Input DataFrame:
>>> df
NE Name Subrack ID pattern
0 10100000/01HJ 0 01HJ
1 10100000/01HL&10100000/02HL&10100000/03HL&10100000/10HL 1 01HJ
2 10100000/01HL&10100000/02HL&10100000/03HL&10100000/10HL 0 01HJ
3 10100000/01HL&10100000/02HL&10100000/03HL&10100000/10HL 2 01HJ
4 10100000/01HL&10100000/02HL&10100000/03HL&10100000/10HL 3 01HJ
CodePudding user response:
Here is a basic approach without using regular expressions:
- Use the
str.split('/')method on the column to return a series of lists, each list containing the substrings in between the slashes. applya function to that series which returns the first four characters of each list element, except the first one. You can use thelambdakeyword to concisely define such a function within theapplycall.
import pandas as pd
df = pd.DataFrame({'col': ['101000000/01HJ',
'1010000/01HL&101/02HL&1010/03HL&04/10HL']})
df['col'].str.split('/').apply(lambda seq: [x[:4] for x in seq[1:]])
0 [01HJ]
1 [01HL, 02HL, 03HL, 10HL]
Name: col, dtype: object