An example url that I'm trying to collect the values from has this pattern:
https://int.soccerway.com/matches/2021/08/18/canada/canadian-championship/hfx-wanderers/blainville/3576866/
The searched value always starts at the seventh / and ends at the ninth /:
/canada/canadian-championship/
The method I know how to do is using LEFT FIND and RIGHT FIND, but it is very archaic, I believe there is a better method for this need.
CodePudding user response:
You can use =REGEXTRACT() to match part of the string with a regular expression:
For example, If A1 = https://int.soccerway.com/matches/2021/08/18/canada/canadian-championship/hfx-wanderers/blainville/3576866/ ,
then
=REGEXEXTRACT(A1, "\/[^\/]*\/[^\/]*\/[^\/]*\/[^\/]*\/[^\/]*\/[^\/]*(\/[^\/]*\/[^\/]*\/)")
returns
/canada/canadian-championship/
Explanation: \/ is '/' escaped. [^\/]* matches any non '/' character 0 or more times. \/[^\/]* is repeated 6 times. () captures a specific part of the string as a group to be returned. Finally (\/[^\/]*\/[^\/]*\/) matches the essential part we want.
CodePudding user response:
Little bit different approach.
=REGEXEXTRACT(SUBSTITUTE(SUBSTITUTE(A1,"/","|",9),"/","|",7),"\|(.*?)\|")

CodePudding user response:
The searched value always starts at the seventh
/and ends at the ninth/:
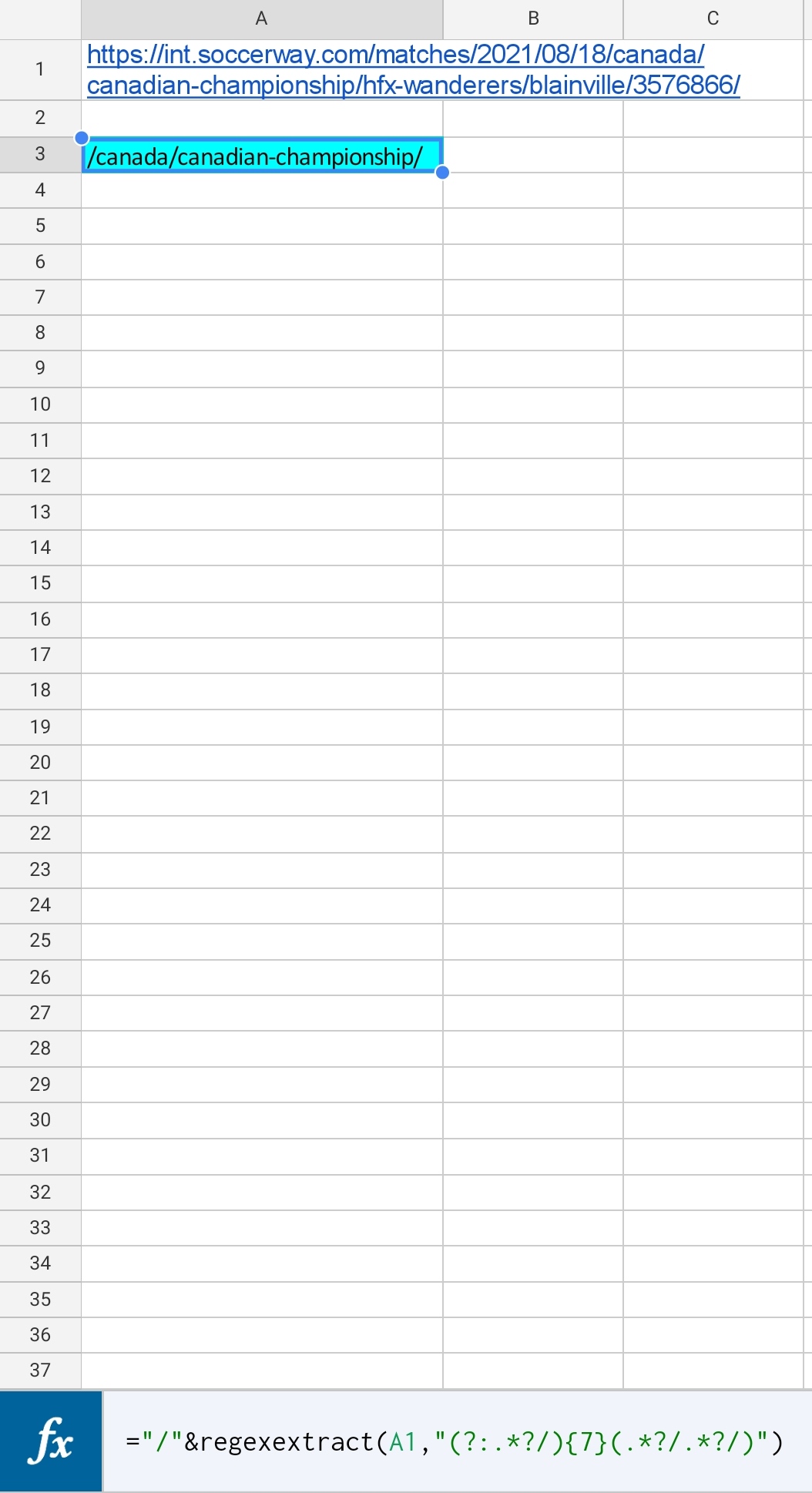
Here's another way you can do it:
="/"®exextract(A1,"(?:.*?/){7}(.*?/.*?/)")
CodePudding user response:
Another alternative:
="/"&textjoin("/", 1, query(split(A1, "/"), "Select Col7, Col8"))&"/"