I've this dataframe:
import pandas as pd
data = {'date': ['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04', '2021-01-05', '2021-01-01', '2021-01-03', '2021-01-04','2021-01-01', '2021-01-02', '2021-01-03','2021-01-01','2021-01-05'],
'user_id': [1, 1, 1, 1, 1,2,2,2,3,3,3,4,5],
'days': [1,2,3,4,5,1,1,2,1,2,3,1,1],
'date_start': ['2021-01-01','NaT','NaT','NaT','NaT','2021-01-01','2021-01-03',"NaT",'2021-01-01','NaT','NaT','2021-01-01','2021-01-05']
}
origin_df = pd.DataFrame(data)
The objective is to count the consecutive days of users. Suppose the user has one day without activity the counter restart. This is the case of user two, as you can see in the image:
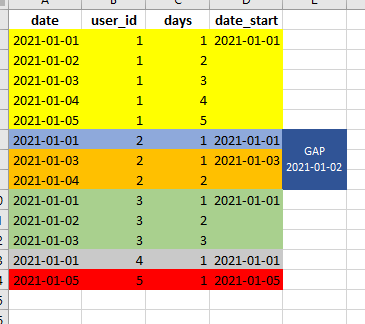
I'm trying to create a data frame that has date_start.
uniqueid_df.loc[(uniqueid_df['days']==1), 'date_start'] = uniqueid_df['date']
Which creates the following new column.
date user_id days date_start
0 2021-01-01 1 1 2021-01-01
5 2021-01-02 1 2 NaT
7 2021-01-03 1 3 NaT
10 2021-01-04 1 4 NaT
12 2021-01-05 1 5 NaT
2 2021-01-01 2 1 2021-01-01
8 2021-01-03 2 1 2021-01-03
11 2021-01-04 2 2 NaT
3 2021-01-01 3 1 2021-01-01
6 2021-01-02 3 2 NaT
9 2021-01-03 3 3 NaT
4 2021-01-01 4 1 2021-01-01
13 2021-01-05 5 1 2021-01-05
But my problem is to create the date_end in case the user, like user_id, has a gap. I'm trying grouping by two columns:
GroupBy Two Columns
df = origin_df.groupby(['date','user_id']).agg({'days':'max'})
Output:
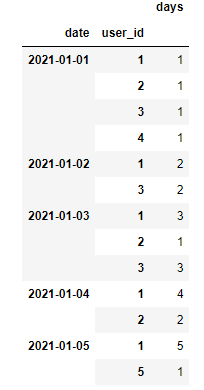
And make a ranking to take the max date for a user.
cols = ['user_id','days']
origin_df['Rank'] = origin_df.sort_values(cols, ascending=False).groupby(cols, sort=False).ngroup() 1
Output:
date user_id days date_start Rank
0 2021-01-01 1 1 2021-01-01 12
1 2021-01-02 1 2 NaT 11
2 2021-01-03 1 3 NaT 10
3 2021-01-04 1 4 NaT 9
4 2021-01-05 1 5 NaT 8
5 2021-01-01 2 1 2021-01-01 7
6 2021-01-03 2 1 2021-01-03 7
7 2021-01-04 2 2 NaT 6
8 2021-01-01 3 1 2021-01-01 5
9 2021-01-02 3 2 NaT 4
10 2021-01-03 3 3 NaT 3
11 2021-01-01 4 1 2021-01-01 2
12 2021-01-05 5 1 2021-01-05 1
My output desire is to convert the data frame we can see in the spreadsheet in something like that:
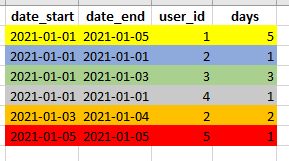
Where you can see that the cases similar to user_id 2 they are not lost.
CodePudding user response:
IIUC, do you want?
import pandas as pd
data = {'date': ['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04', '2021-01-05', '2021-01-01', '2021-01-03', '2021-01-04','2021-01-01', '2021-01-02', '2021-01-03','2021-01-01','2021-01-05'],
'user_id': [1, 1, 1, 1, 1,2,2,2,3,3,3,4,5],
'days': [1,2,3,4,5,1,1,2,1,2,3,1,1],
'date_start': ['2021-01-01','NaT','NaT','NaT','NaT','2021-01-01','2021-01-03',"NaT",'2021-01-01','NaT','NaT','2021-01-01','2021-01-05']
}
origin_df = pd.DataFrame(data).replace('NaT',np.nan)
origin_df['date_start'] = origin_df['date_start'].ffill()
df_out = origin_df.groupby(['date_start','user_id'], as_index=False)\
.agg(date_start=('date','min'),
date_end=('date','max'),
days=('date','count'))
print(df_out)
Output:
user_id date_start date_end days
0 1 2021-01-01 2021-01-05 5
1 2 2021-01-01 2021-01-01 1
2 3 2021-01-01 2021-01-03 3
3 4 2021-01-01 2021-01-01 1
4 2 2021-01-03 2021-01-04 2
5 5 2021-01-05 2021-01-05 1
CodePudding user response:
computing the cumulated consecutive days
You can convert to datetime and use the date difference to compute a group. Then use groupby cumcount:
origin_df['date'] = pd.to_datetime(origin_df['date'])
group = origin_df.groupby('user_id')['date'].diff().ne('1d').cumsum()
origin_df['days'] = origin_df.groupby(group).cumcount().add(1)