Just a random q. If there's a dataframe, df, from the Boston Homes ds, and I'm trying to do EDA on a few of the columns, set to a variable feature_cols, which I could use afterwards to check for na, how would one go about this? I have the following, which is throwing an error:
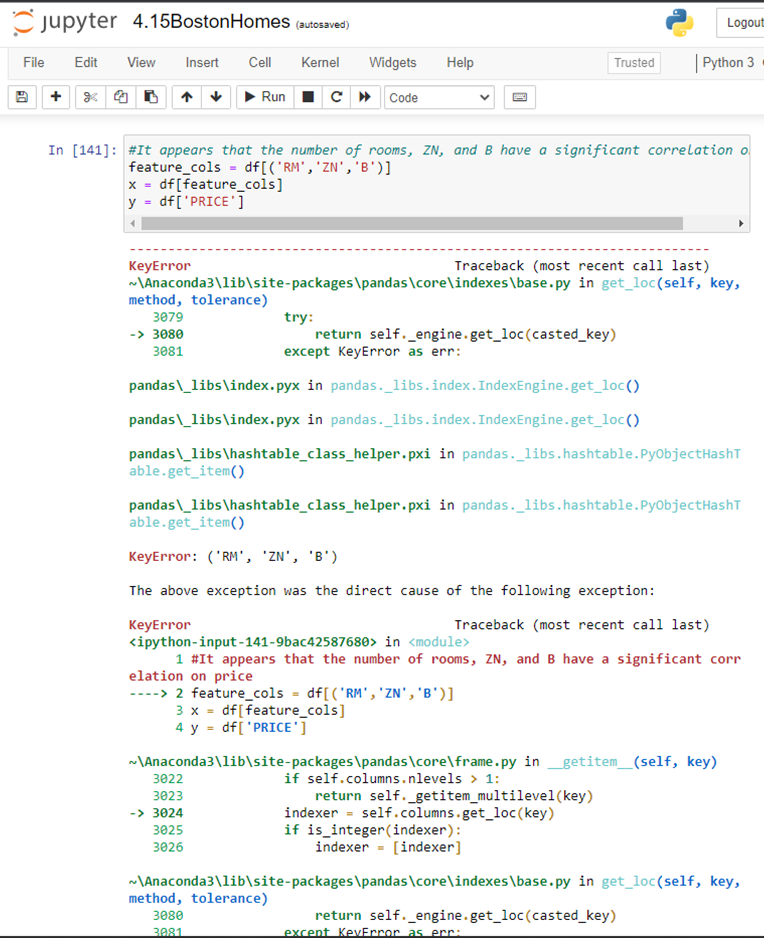
This is what I was hoping to try to do after the above:
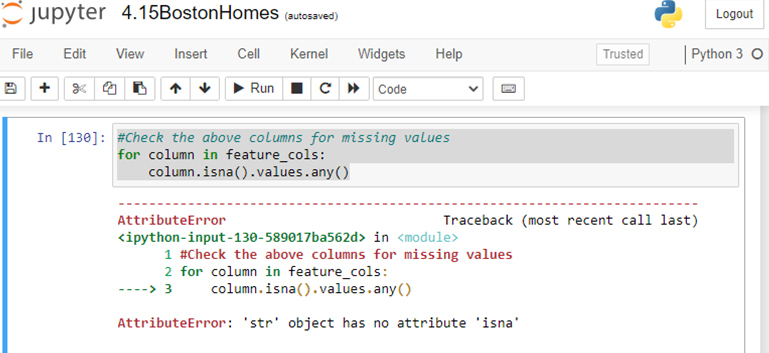
Any feedback would be greatly appreciated. Thanks in advance.
CodePudding user response:
There are two problems in your pictures. First is a keyError, because if you want to access subset of columns of a dataframe, you need to pass the names of the columns in a list not a tuple, so the first line should be
feature_cols = df[['RM','ZN','B']]
However, this will return a dataframe with three columns. What you want to use in the for loop can not work with pandas. We usually iterate over rows, not columns, of a dataframe, you can use the one line:
df.isna().sum()
This will print all names of columns of the dataframe along with the count of the number of missing values in each column. Of course, if you want to check only a subset of columns, you can. replace df buy df[list_of_columns_names].
CodePudding user response:
You need to store the names of the columns only in an array, to access multiple columns, for example
feature_cols = ['RM','ZN','B']
now accessing it as
x = df[feature_cols]
Now to iterate on columns of df, you can use
for column in df[feature_cols]:
print(df[column]) # or anything
As per your updated comment,. if your end goal is to see null counts only, you can achieve without looping., e.g
df[feature_cols].info(verbose=True,null_count=True)