Here is my code
with open('book1.csv', 'r') as f:
for key, value in c.items():
if value == max_value:
print(key)
if key in dict_from_csv.keys():
print(dict_from_csv[key])
It prints out only 2 keys but I need all duplicate keys.
this is my CSV it consists of name of projects and costs.
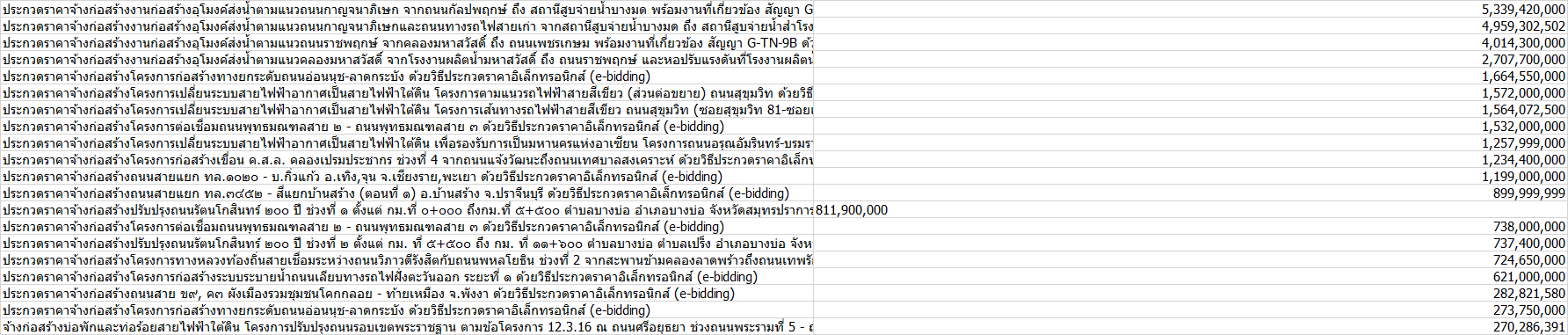
my full code is
c = rank(results)
max_value = max(values)
newlist1_value = values
newlist1_value.remove(max(values))
second_max_value = max(newlist1_value)
newlist2_value = newlist1_value
newlist2_value.remove(max(newlist1_value))
third_max_value = max(newlist2_value)
keys = []
mydict = {}
with open('book1.csv', mode='r') as inp:
reader = csv.reader(inp)
dict_from_csv = {rows[2]: rows[3] for rows in reader}
for key, value in c.items():
if value == max_value:
print(key)
if key in dict_from_csv.keys():
print(dict_from_csv[key])
my goal is to print out all the duplicate names of projects with all the costs.
CodePudding user response:
When you are creating dict from csv, duplicate keys are overwritten. Use list instead, then keep track of already seen keys in dict. If there are more than 2 values for a given key print them.
with open('book1.csv', 'r') as f:
reader = csv.reader(f)
list_from_csv = [[row[2], row[3]] for row in reader]
max_value = max([x[1] for x in list_from_csv])
dic = {}
res = []
for li in list_from_csv:
#iterate over project name and and cost
key, value = li
# key is name of project, value is cost
if value == max_value:
print('max value', *li)
if key in dic:
#check if the project name is already in dic where you store values
#for same project name append value to already seen values
dic[key].append(value)
if key not in dic:
# if key is not in dic create new with list of value, so you can append to it later
dic[key] = [value]
# print(dic)
for key, value in dic.items():
# finally iterate over stored projects with list of values
# if there are more than one value , it means it has duplicates so
# print them
if len(value) > 1:
print(key, *value)