Data:
structure(list(Month_Name = c("September", "September", "September",
"September", "September", "September", "September", "September",
"September", "September", "September", "September", "September",
"September", "September", "September", "September", "September",
"September", "September", "September", "September", "September",
"September", "September", "September", "September", "September",
"September", "September", "October", "October", "October", "October",
"October", "October", "October", "October", "October", "October",
"October", "October", "October", "October", "October", "October",
"October", "October", "October", "October", "October", "October",
"October", "October", "October", "October", "October", "October",
"October", "October", "October", "November", "November", "November",
"November", "November", "November", "November", "November", "November",
"November", "November", "November", "November", "November", "November",
"November", "November", "November", "November", "November", "November",
"November", "November", "November", "November", "November", "November",
"November", "November", "November", "December", "December", "December",
"December", "December", "December", "December", "December", "December",
"December", "December", "December", "December", "December", "December",
"December", "December", "December", "December", "December", "December",
"December", "December", "December", "December", "December", "December",
"December", "December", "December", "December", "January", "January",
"January", "January", "January", "January", "January", "January",
"January", "January", "January", "January", "January", "January",
"January", "January", "January", "January", "January", "January",
"January", "January", "January", "January", "January", "January",
"January", "January", "January", "January"), Mins_Work = c(435L,
350L, 145L, 135L, 15L, 60L, 60L, 390L, 395L, 395L, 315L, 80L,
580L, 175L, 545L, 230L, 435L, 370L, 255L, 515L, 330L, 65L, 115L,
550L, 420L, 45L, 266L, 196L, 198L, 220L, 17L, 382L, 0L, 180L,
343L, 207L, 263L, 332L, 0L, 0L, 259L, 417L, 282L, 685L, 517L,
111L, 64L, 466L, 499L, 460L, 269L, 300L, 427L, 301L, 436L, 342L,
229L, 379L, 102L, 146L, NA, 94L, 345L, 73L, 204L, 512L, 113L,
135L, 458L, 493L, 552L, 108L, 335L, 395L, 508L, 546L, 396L, 159L,
325L, 747L, 650L, 377L, 461L, 669L, 186L, 220L, 410L, 708L, 409L,
515L, 413L, 166L, 451L, 660L, 177L, 192L, 191L, 461L, 637L, 297L,
601L, 586L, 270L, 479L, 0L, 480L, 397L, 174L, 111L, 0L, 610L,
332L, 345L, 423L, 160L, 611L, 0L, 345L, 550L, 324L, 427L, 505L,
632L, 560L, 230L, 495L, 235L, 522L, 654L, 465L, 377L, 260L, 572L,
612L, 594L, 624L, 237L, 0L, 38L, 409L, 634L, 292L, 706L, 399L,
568L, 0L, 694L, 298L, 616L, 553L, 581L, 423L)), row.names = c(NA,
-152L), class = "data.frame")
Problem:
Not sure why, but I'm having difficulties figuring out how to use dplyr right now to get what I want out of summarize this time. Basically, I have a grouped sum, mean, and per week table for minutes of work:
library(tidyverse)
work_slack %>%
group_by(Month_Name) %>%
summarize(Sum_Work = round((sum(Mins_Work,na.rm = T))/60),
Mean_Work_Day = round(mean(Mins_Work,na.rm = T)/60),
Per_Week_Sum = round((sum(Mins_Work,na.rm = T))/60/4))%>%
arrange(desc(Sum_Work))
Which gives me these values so far when I add them into a gt table:
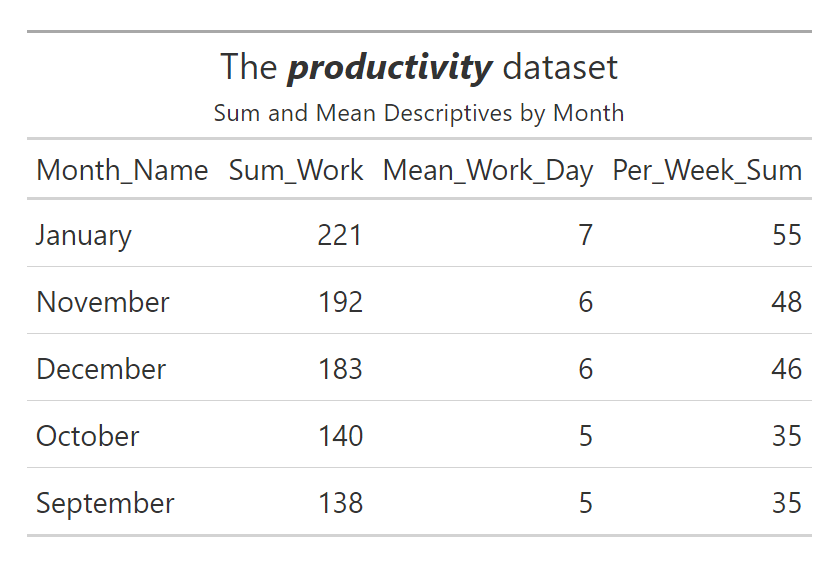
However, I wanna find a way to summarize how many times there was no work done. I'm having trouble trying to figure out which command within dplyr can get me this. The best idea ive had so far is this, which doesnt work:
work_slack %>%
group_by(Month_Name) %>%
summarize(Sum_Work = round((sum(Mins_Work,na.rm = T))/60),
Mean_Work_Day = round(mean(Mins_Work,na.rm = T)/60),
Per_Week_Sum = round((sum(Mins_Work,na.rm = T))/60/4),
Breaks = count(Mins_Work = 0))%>%
arrange(desc(Sum_Work))
Basically, what I need is a way to summarize the number of unique times per month Mins_Work equaled zero. Hopefully that makes sense.
CodePudding user response:
Is this what you need:
df %>%
group_by(Month_Name) %>%
summarize(Sum_Work_0 = sum(Mins_Work==0,na.rm = T))
# A tibble: 5 × 2
Month_Name Sum_Work_0
<chr> <int>
1 December 3
2 January 2
3 November 0
4 October 3
5 September 0
CodePudding user response:
You almost get it right. The trick is to sum all the values that equals 0.
work_slack %>%
group_by(Month_Name) %>%
summarize(Sum_Work = round((sum(Mins_Work,na.rm = T))/60),
Mean_Work_Day = round(mean(Mins_Work,na.rm = T)/60),
Per_Week_Sum = round((sum(Mins_Work,na.rm = T))/60/4),
Breaks = sum(Mins_Work == 0, na.rm=T))%>%
arrange(desc(Sum_Work))
# A tibble: 5 x 5
Month_Name Sum_Work Mean_Work_Day Per_Week_Sum Breaks
<chr> <dbl> <dbl> <dbl> <int>
1 January 221 7 55 2
2 November 192 6 48 0
3 December 183 6 46 3
4 October 140 5 35 3
5 September 138 5 35 0