I need to write a SQL query which records just one record per 20 minute blocks of a datetime column, partitioned by another field.
For example, if I were to run a query pulling back all data from my table for a specific timeframe I might see the following. If I were to do a COUNT(1) on this data I will get a result of 29.
What I want is to be able to only count only one record every 20 minutes, starting with the MIN(ActionTime). If you look at the below, I would only want to return a count of 4.
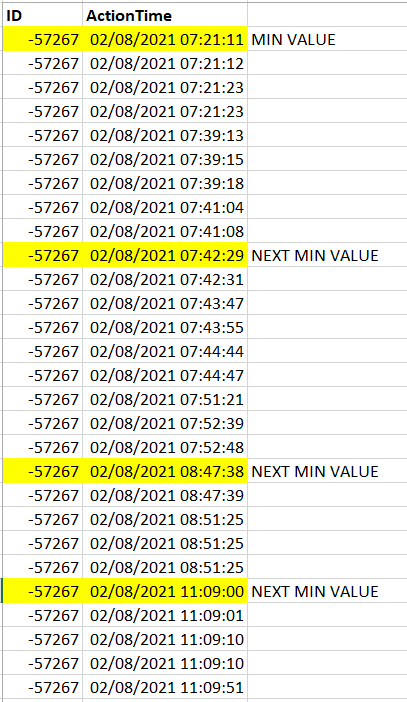
I have the following example
CREATE TABLE #tmp (ID INT, ActionTime DATETIME)
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:21:11')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:21:12')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:21:23')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:21:23')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:39:13')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:39:15')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:39:18')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:41:04')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:41:08')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:42:29')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:42:31')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:43:47')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:43:55')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:44:44')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:44:47')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:51:21')
;
WITH data
AS (SELECT t.*,
ROW_NUMBER() OVER (ORDER BY t.ActionTime) rn
FROM #tmp t
),
cte
AS (SELECT d.*,
d.ActionTime AS first_search_time
FROM data d
WHERE rn = 1
UNION ALL
SELECT d.*,
CASE
WHEN d.ActionTime > DATEADD(MINUTE, 20, c.first_search_time) THEN
d.ActionTime
ELSE
c.first_search_time
END
FROM cte c
INNER JOIN data d
ON d.rn = c.rn 1
)
SELECT c.*,
DENSE_RANK() OVER (PARTITION BY c.ID ORDER BY first_search_time) grp
INTO #tmp_dense_rank
FROM cte c
OPTION (MAXRECURSION 0);
SELECT ID, COUNT(DISTINCT grp) AS Logins
FROM #tmp_dense_rank
GROUP BY ID
DROP TABLE #tmp
DROP TABLE #tmp_dense_rank
If I run this example it works as expected and returns a count of 4. However, when I extend the date range to search for say a months worth of data, it is taking forever to run and the estimated execution plan is saying there are 87 million rows. A straight select for the month only returns 40500 rows. So is the CTE doing something wrong recursively or is there a Cartesian issue?
Sorry, this wasn't really the easiest to explain or demonstrate but I hope I have explained it enough for you to understand what I need. Its driving me mad. Also, if there is better way of doing this then please let me know.
CodePudding user response:
My approach was to generate a list of breaks of 20 minutes width each, then get the min actiontime in each break.
CREATE TABLE #tmp (ID INT, ActionTime DATETIME)
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:21:11')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:21:12')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:21:23')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:21:23')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:39:13')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:39:15')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:39:18')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:41:04')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:41:08')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:42:29')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:42:31')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:43:47')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:43:55')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:44:44')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:44:47')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:51:21');
--generate a list of the 20-minute breaks
--DROP TABLE #breaks;
CREATE TABLE #breaks (break_id int, break_from_ts DATETIME, break_to_ts DATETIME);
DECLARE @from int = 1;
DECLARE @to int = 10000;
DECLARE @minActionTime datetime = (SELECT MIN(ActionTime) AS min_ActionTime FROM #tmp);
WITH intlist
AS (SELECT num = @from
UNION ALL
SELECT num 1
FROM intlist
WHERE num 1 <= @to)
INSERT INTO #breaks (break_id, break_from_ts, break_to_ts)
SELECT 1 AS break_id, @minActionTime AS break_from_ts, DATEADD(MINUTE,20,@minActionTime) AS break_to_ts
UNION ALL
SELECT intlist.num 1, DATEADD(MINUTE,20 * intlist.num,@minActionTime) AS break_from_ts, DATEADD(MINUTE,20 * (intlist.num 1),@minActionTime) AS break_to_ts
FROM intlist
OPTION (maxrecursion 0);
--a list of 10001 breaks each 20 minutes in width
SELECT * FROM #breaks;
--get the min ActionTime by break_id etc
SELECT id, COUNT(*) AS logins
FROM (
SELECT x.id, y.break_id, y.break_from_ts, y.break_to_ts, MIN(x.ActionTime) AS min_ActionTime
FROM #tmp x
INNER JOIN #breaks y ON x.ActionTime >= break_from_ts AND x.ActionTime < break_to_ts
GROUP BY x.id, y.break_id, y.break_from_ts, y.break_to_ts
) x
GROUP BY id;
Of course, the number of breaks you put in that intlist CTE is entirely up to you. You may want to calculate the total number of minutes under consideration and scale the CTE appropriately.
EDIT: As an afterthought, you will notice that CTEs become slow if too large, so you may want to consider creating a permanent table in your database that simply contains a very long list of integers, so you can use it for this purpose and other purposes, rather than using a recurring CTE.
CodePudding user response:
If I'm understanding correctly then this should work:
CREATE TABLE #tmp (ID INT, ActionTime DATETIME)
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:21:11')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:21:12')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:21:23')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:21:23')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:39:13')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:39:15')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:39:18')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:41:04')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:41:08')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:42:29')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:42:31')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:43:47')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:43:55')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:44:44')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:44:47')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:51:21')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:52:39')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 07:52:48')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 08:47:38')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 08:47:39')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 08:51:25')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 08:51:25')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 08:51:25')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 11:09:00')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 11:09:01')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 11:09:10')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 11:09:10')
INSERT INTO #tmp VALUES (-57267, '02/08/2021 11:09:51')
;
with rolledup as (
SELECT #tmp.ID,
round(
CAST(actiontime - logintimes.firstlogin AS float) * 72.0, 0, 1) as period
from #tmp
inner join (
select ID,
min(actiontime) as firstlogin
from #tmp
group by ID
) logintimes on logintimes.ID = #tmp.id
group by #tmp.ID, round(CAST(actiontime - logintimes.firstlogin AS float) * 72.0,0,1)
)
select ID,
count(1) as Logins
from rolledup
group by ID
drop table #tmp
Running that gives me -57267,4