The definition of spark job is:
Job- A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you'll see this term used in the driver's logs.
So, why is it that each spark-submit creates just one job id in dataproc console that I can see?
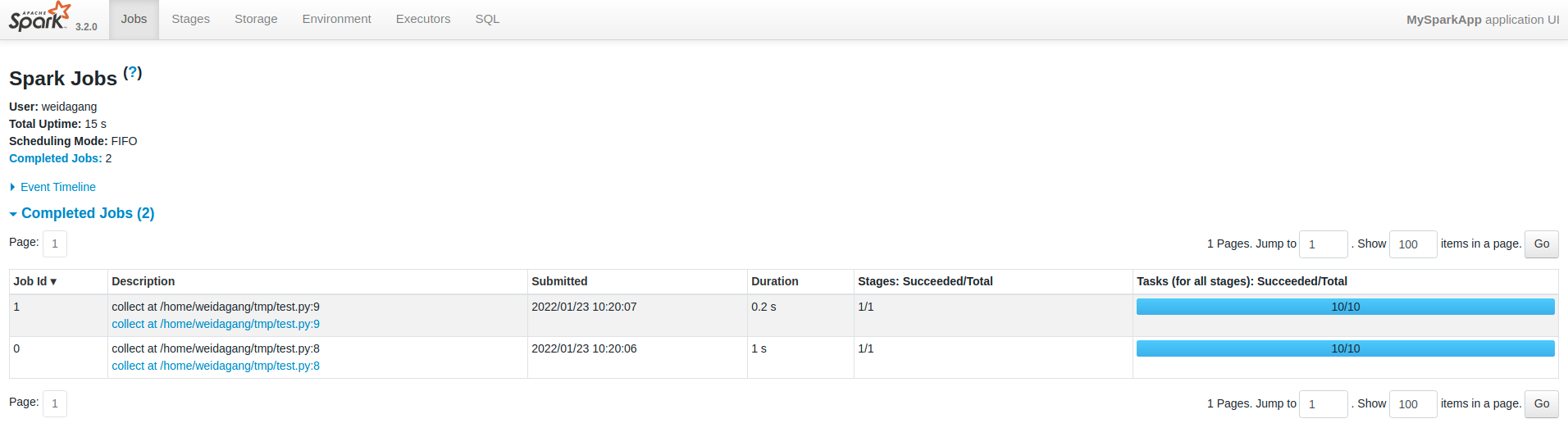
Example: The following application should have 2 spark jobs
sc.parallelize(range(1000),10).collect()
sc.parallelize(range(1000),10).collect()
CodePudding user response:
There is a difference between Dataproc job and Spark job. When you submit the script through Dataproc API/CLI, it creates a Dataproc job, which in turn calls spark-submit to submit the script to Spark. But inside Spark, the code above does create 2 Spark jobs. You can see it in the Spark UI: