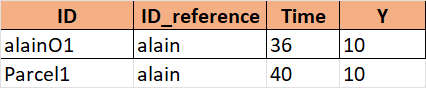
I am relatively new to Python and NetworkX and I am facing difficulties in figuring out how some things work out. I have a node list and a parcel list in two excel sheets. I successfully added the nodes but I want to add the parcels as nodes in the node list, however, I get the error KeyError 1. The parcels have different attributes, hence the presence of two different sheets. In the parcel sheet, I only need the attributes "ID_reference", "Time", and "Y".
This is the headings of the excel sheet for the node list

This is the headings of the excel sheet for the parcel list

Here is the code:
g = nx.DiGraph()
#Loop through rows of edge list:
for i, elrow in edgelist.iterrows():
g.add_edge(elrow[0], elrow[1], attr_dict=elrow[2:].to_dict())
#Loop through the rows in the node list
for i, nlrow in nodelist.iterrows():
#print(nlrow[1:])
g.nodes[nlrow['ID']].update(nlrow[1:].to_dict())
#Loop through the rows in the node list
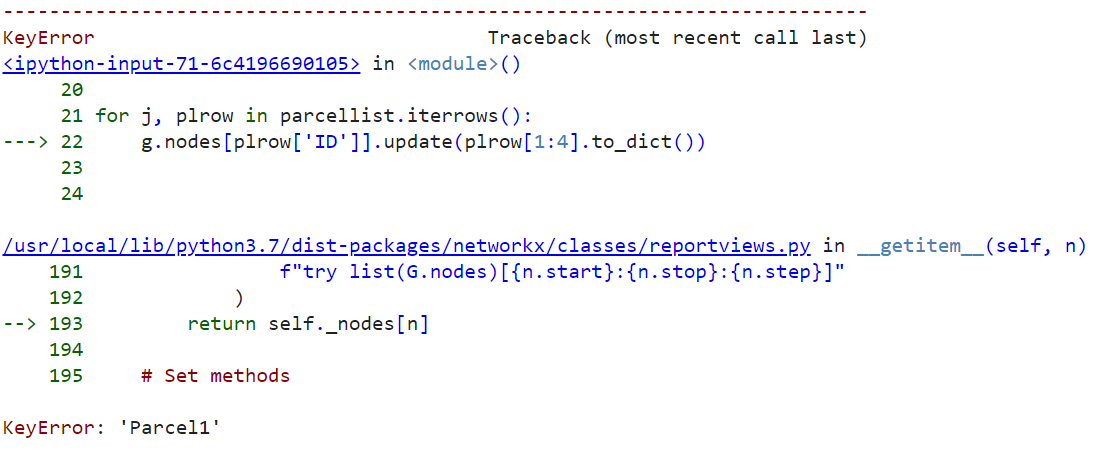
for j, plrow in parcellist.iterrows():
g.nodes[plrow['ID']].update(plrow[1:4].to_dict())
I would like the code to the node list to take from the parcel list to look like this
This is the error I get when I run the following code:
CodePudding user response:
It's possible that the dataframe contains string representations of integer IDs (e.g. '1' vs 1). If so, the problem can be answered in a way similar to this answer:
- check the pandas dataframes and enforce the same dtype on all of them, preferably
int:
nodelist['ID'] = nodelist['ID'].astype('int')
parcellist['ID'] = parcellist['ID'].astype('int')
edgelist['ID'] = edgelist['ID'].astype('int')
edgelist['ID_reference'] = edgelist['ID_reference'].astype('int')