I have some hourly data over 24 hrs across a year, by 7 groups. When I fit a gam (mgcv::gam) I use the by= argument to produce 7 different fitted lines - it produces some odd looking fits. However when I subset the data to just one of those groups and run the gam again, with no by=Group argument used, the fit looks a lot better and makes sense.
This is a toy example where the change is not so dramatic between the two methods, but my real result is much more drastic when using the by= argument, why would this be?
require(data.table)
require(mgcv)
require(ggplot2)
## create two groups of data, A & B
dtA <- data.table(t = rep(1:12,each=100) , N = c(runif(200, 0.0, 1.0),runif(200, 2.0, 3.0),runif(200, 5.0, 7.0),runif(200, 4.0, 5.0),runif(200, 1.0, 2.0),runif(200, 0.0, 1.0)), Group="A")
dtB <- data.table(t = rep(1:12,each=100) , N = c(runif(200, 20.0, 22.0),runif(200, 14.0, 16.0),runif(200, 6.0, 7.0),runif(200, 5.0, 6.0),runif(200, 12.0, 15.0),runif(200, 17.0, 20.0)), Group="B")
## put the data together, set the group as a factor
dt_gp <- rbindlist(list(dtA,dtB), use.names = T)
dt_gp[, Group := factor(Group, levels=c("A","B"))]
## create the gam , using the by grouping, and then fit to a blank table
gam1 <- gam(N ~ s(t,k=8, bs="cc", by=Group), data = dt_gp)
dt_fit1 <- data.table(t=rep(c(1:12),2), Group=rep(c("A","B"), each=12))
dt_fit1[, Group := factor(Group, levels=c("A","B"))]
fits1 = predict(gam1, newdata=dt_fit1, type='response', se=T)
predicts1 = as.data.table(data.frame(dt_fit1, fits1))
## now subset GpA data and run and recreate GAM and fitted line.
dt <- dt_gp[Group=="A"]
dt[,Group:=NULL]
gam2 <- gam(N ~ s(t,k=8, bs="cc"), data = dt)
dt_fit2 <- data.table(t=1:12)
fits2 = predict(gam2, newdata=dt_fit2, type='response', se=T)
predicts2 = as.data.table(data.frame(dt_fit2, fits2))
## plot to see difference (add Group to 2nd prediction for facet in plot)
predicts2[,Group:="A"]
ggplot()
geom_line(data=predicts1, aes(x=t, y=fit), colour="blue")
geom_line(data=predicts2, aes(x=t, y=fit), colour="red")
geom_point(data=dt_gp, aes(x=t,y=N), colour="grey50")
facet_wrap(~Group, nrow=2, scales="free_y")
ggtitle("GAM on numbers grouped by A & B (numbers in A identical in both cases)")
theme_bw()
theme(axis.text.x = element_text(size=12),
axis.text.y = element_text(size=12),
axis.title = element_text(size=16),
legend.title=element_blank())
Red line is when I separate out the data, blue lines are done in a grouping manner. Does the grouping function in mgcv::gam() not separate the data? As the more I make A & B 'different', the worse the blue lines fit the raw data dots.
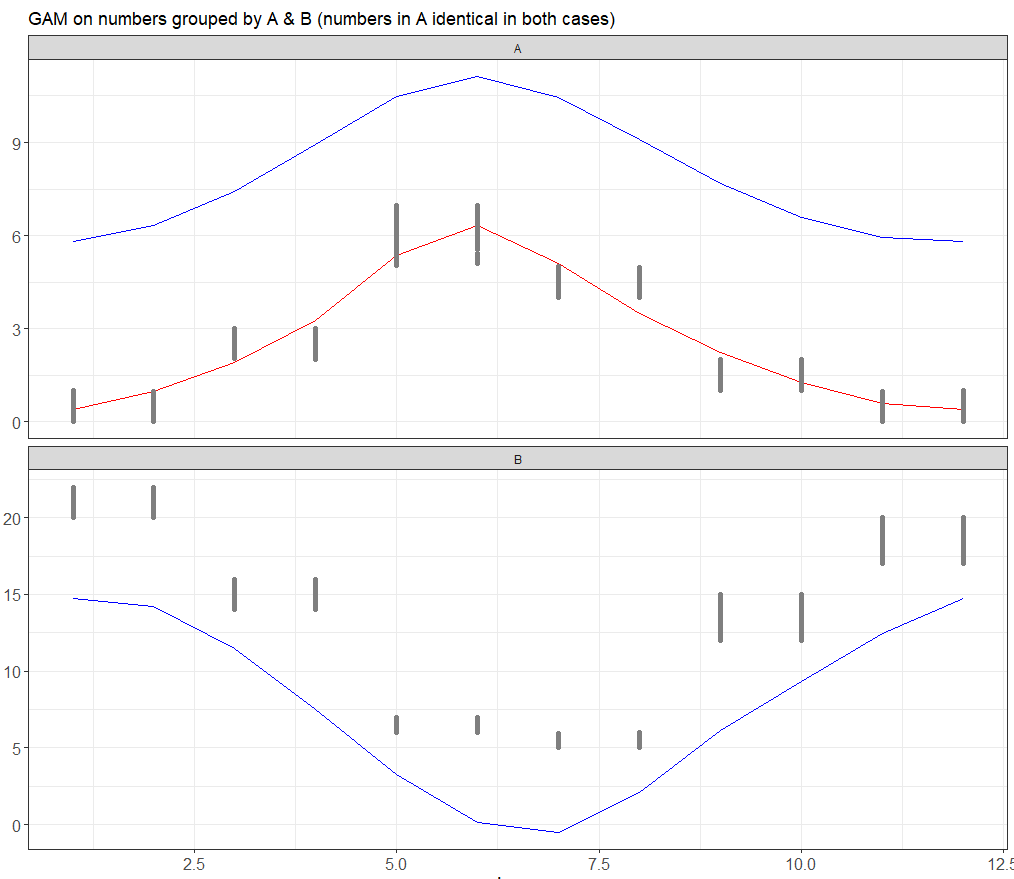
CodePudding user response:
From the documentation for the s function in mgcv:
In the factor
byvariable case a replicate of the smooth is produced for each factor level (these smooths will be centered, so the factor usually needs to be added as a main effect as well). Seegam.modelsfor further details.
So it looks like you'll want to include Group in your formula outside the call to s as well, e.g.,
gam1 <- gam(N ~ Group s(t,k=8, bs="cc", by=Group), data = dt_gp).