My code:
import csv
import operator
first_csv_file = open('/Users/jawadmrahman/Downloads/account-cleanup-3 array/example.csv', 'r ')
csv_sort = csv.reader(first_csv_file, delimiter=',')
sort = sorted(csv_sort, key=operator.itemgetter(0))
sorted_csv_file = open('new_sorted2.csv', 'w ', newline='')
write = csv.writer(sorted_csv_file)
for eachline in sort:
print (eachline)
write.writerows(eachline)
I have an example csv file:
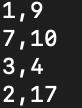
I want to sort by the first column and get the results in this fashion:
1,9
2,17,
3,4
7,10
With the code posted above, this is how I am getting it now:
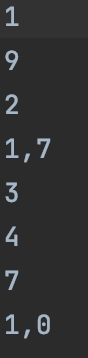
How do I fix this?
CodePudding user response:
As JonSG pointed out in the comments to your original post, you're calling writerows() (plural) on a single row, eachline.
Change that last line to write.writerow(eachline) and you'll be good.
Looking at the problem in depth
writerows() expects "a list of a list of values". The outer list contains the rows, the inner list for each row is effectively the cell (column for that row):
sort = [
['1', '9'],
['2', '17'],
['3', '4'],
['7', '10'],
]
writer.writerows(sort)
will produce the sorted CSV with two columns and four rows that you expect (and your print statement shows).
When you call writerows() with a single row:
for eachline in sort:
writer.writerows(eachline)
you get some really weird output:
it interprets
eachlineat the outer list containing a number of rows, which means...it interprets each item in
eachlineas a row having individual columns...and each item in
eachlineis a Python sequence, string, sowriterows()iterates over each character in your string, treating each character as its own column...['1','9']is seen as two single-column rows,['1']and['9']:1 9['2', '17']is seen as the single-column row['2']and the double-column row['1', '7']:2 1,7