I have a performance critical C code where > 90% of the time is spent doing one basic operation:
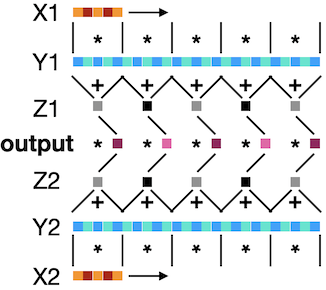
The C code I am using is:
static void function(double *X1, double *Y1, double *X2, double *Y2, double *output) {
double Z1, Z2;
int i, j, k;
for (i = 0, j = 0; i < 25; j ) { // sweep Y
Z1 = 0;
Z2 = 0;
for (k = 0; k < 5; k , i ) { // sweep X
Z1 = X1[k] * Y1[i];
Z2 = X2[k] * Y2[i];
}
output[j] = Z1*Z2;
}
}
The lengths are fixed (X is 5; Y is 25; the output is 5). I have tried everything I know to make this faster. When I compile this code using clang with -O3 -march=native -Rpass-analysis=loop-vectorize -Rpass=loop-vectorize -Rpass-missed=loop-vectorize, I get this message:
remark: the cost-model indicates that vectorization is not beneficial [-Rpass-missed=loop-vectorize]
But I assume the way to make this faster is with SIMD somehow. Any suggestions would be appreciated.
CodePudding user response:
Try the following version, it requires SSE2 and FMA3. Untested.
void function_fma( const double* X1, const double* Y1, const double* X2, const double* Y2, double* output )
{
// Load X1 and X2 vectors into 6 registers; the instruction set has 16 of them available, BTW.
const __m128d x1_0 = _mm_loadu_pd( X1 );
const __m128d x1_1 = _mm_loadu_pd( X1 2 );
const __m128d x1_2 = _mm_load_sd( X1 4 );
const __m128d x2_0 = _mm_loadu_pd( X2 );
const __m128d x2_1 = _mm_loadu_pd( X2 2 );
const __m128d x2_2 = _mm_load_sd( X2 4 );
// 5 iterations of the outer loop
const double* const y1End = Y1 25;
while( Y1 < y1End )
{
// Multiply first 2 values
__m128d z1 = _mm_mul_pd( x1_0, _mm_loadu_pd( Y1 ) );
__m128d z2 = _mm_mul_pd( x2_0, _mm_loadu_pd( Y2 ) );
// Multiply accumulate next 2 values
z1 = _mm_fmadd_pd( x1_1, _mm_loadu_pd( Y1 2 ), z1 );
z2 = _mm_fmadd_pd( x2_1, _mm_loadu_pd( Y2 2 ), z2 );
// Horizontal sum both vectors
z1 = _mm_add_sd( z1, _mm_unpackhi_pd( z1, z1 ) );
z2 = _mm_add_sd( z2, _mm_unpackhi_pd( z2, z2 ) );
// Multiply accumulate the last 5-th value
z1 = _mm_fmadd_sd( x1_2, _mm_load_sd( Y1 4 ), z1 );
z2 = _mm_fmadd_sd( x2_2, _mm_load_sd( Y2 4 ), z2 );
// Advance Y pointers
Y1 = 5;
Y2 = 5;
// Compute and store z1 * z2
z1 = _mm_mul_sd( z1, z2 );
_mm_store_sd( output, z1 );
// Advance output pointer
output ;
}
}
It’s possible to micro-optimize further by using AVX, but I’m not sure it’s going to help much because the inner loop is too short. I think that these two extra FMA instructions are cheaper than the overhead of computing horizontal sum of the 32-byte AVX vectors.
CodePudding user response:
You can at least process 2 elements at a time by loading the lower and upper half registers separately. Unrolling i by two may give a small edge...
The __restrict keyword, if applicable, allows the five constant coefficients X1[0..4], X2[0..4] to be preloaded. If X1 or X2 partially alias output, it's better to let the compiler know it (by using the same array). In this way, as the complete function is unrolled, the compiler will not reload any element unnecessarily.
typedef double __attribute__((vector_size(16))) f2;
void function2(double *X1, double *Y1, double *X2, double *Y2, double *__restrict output) {
double Z1, Z2;
int i = 0, j, k;
for (j = 0; j < 5; j ) { // sweep Y
f2 Z12 = {0.0, 0.0};
for (k = 0; k < 5; k , i ) {
f2 Y12 = {Y1[i], Y2[i]};
f2 X12 = {X1[k], X2[k]};
Z12 = X12 * Y12;
}
output[j] = Z12[0]*Z12[1];
}
}