I have a data frame in which some rows are equal, first I want to subtract the larger date from the smaller date in the rows that are equal, and then finally calculate the average of the dates obtained, which is the average of a few days. But only select dates that have at least two Order_id with one Customer_id, My data frame looks like this:
Customer_id date Order_id
12 22/11/2021 2
12 29/11/2021 2
12 30/11/2021 2
42 10/11/2021 2
42 18/11/2021 2
43 19/11/2021 3
Then subtract the dates: (The last line was not selected because it has one customer_ID and one order_id)
Customer_id date Order_id Subtract_date
12 22/11/2021 2 8
12 29/11/2021 2 8
12 30/11/2021 2 8
42 10/11/2021 2 8
42 18/11/2021 2 8
Then the duplicate rows are deleted and finally the average of the Subtract_date column is taken:
Customer_id date Order_id Subtract_date
12 22/11/2021 2 8
42 10/11/2021 2 8
CodePudding user response:
Try this if I understand correct:
df.groupby(['Customer_id', 'oder_id']).agg(np.ptp).reset_index().rename({'date':'Subtract_date'}, axis = 1)
Output:
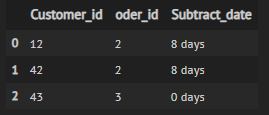
CodePudding user response:
You can run the following to remove customers with 1 order:
cust_to_keep = df.groupby('Customer_id').date.transform('count')
df = df.loc[cust_to_keep>1]
and then leverage Groupby and NamedAggregation to get the desired output:
import datetime as dt
df.groupby(['Customer_id','Order_id']).agg(date=('date','min'),Subtract_date = ('date',lambda x:(x.max()-x.min()).days)).reset_index()