I tried to express my use case in R code as follows:
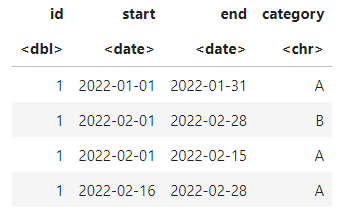
haves <- data.frame(
id = c(1,1,1,1)
, start = c(as.Date('2022-01-01'), as.Date('2022-02-01'), as.Date('2022-02-01'), as.Date('2022-02-16'))
, end = c(as.Date('2022-01-31'), as.Date('2022-02-28'), as.Date('2022-02-15'), as.Date('2022-02-28'))
, category = c("A", "B", "A", "A")
)
haves
wants <- data.frame(
id = c(1,1,1)
, start = c(as.Date('2022-01-01'), as.Date('2022-02-01'), as.Date('2022-02-01'))
, end = c(as.Date('2022-01-31'), as.Date('2022-02-28'), as.Date('2022-02-28'))
, category = c("A", "B", "A")
)
wants
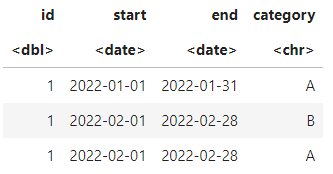
Basically I want to collapse time periods (see last 2 columns in wants) if they are consecutive and contain the same category but also depended on id. Do you think this is possible? A group by id and category and then using min and max on start and end would not work.
CodePudding user response:
Using rle, this should work:
r <- rle(haves$category)$l
haves %>%
mutate(cons = rep(seq(r), r)) %>%
group_by(id, category, cons) %>%
summarise(start = min(start),
end = max(end))
# A tibble: 3 x 5
# Groups: id, category [2]
id category cons start end
<dbl> <chr> <int> <date> <date>
1 1 A 1 2022-01-01 2022-01-31
2 1 A 3 2022-02-01 2022-02-28
3 1 B 2 2022-02-01 2022-02-28
Or with cons = data.table::rleid(category).
CodePudding user response:
This should work but let me know if you have any issues.
First create an ID for blocks of consecutive rows within id & category, then find the blocks within these that are consecutive.
haves %>%
as_tibble() %>%
mutate(
g_id = cumsum( paste0(id, '|', category) != lag(paste0(id, '|', category), n = 1L, default = '&%' ))
) %>%
group_by(id, category, g_id) %>%
mutate(
lag1 = replace_na(lag(end, n = 1L) 1 == start, T)
) %>%
ungroup() %>%
mutate(
g_id2 = cumsum( paste0(g_id, '|', lag1) != lag(paste0(g_id, '|', lag1), n = 1L, default = '&%' ))
) %>%
group_by(id, category, g_id2) %>%
summarise(
start = min(start),
end = max(end)
) %>%
arrange(g_id2)
CodePudding user response:
A data.table option
library(data.table)
unique(
setDT(haves)[
,
`:=`(start = min(start), end = max(end)), rleid(category)
]
)
gives
id start end category
1: 1 2022-01-01 2022-01-31 A
2: 1 2022-02-01 2022-02-28 B
3: 1 2022-02-01 2022-02-28 A