I have a table, df1, containing columns Itemlist1 and Itemlist2 where each cell in this table can contain any number of items starting from 1. Example: there can be 1 item A in one cell, 2 items B, C in another cell and 3 items A, D, E in another.
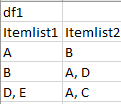
I have another table, df2, with the Price and Cost of each item.
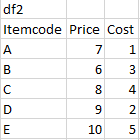
I want to create this final df with 2 new columns added to df1, Totalprice and Totalcost. The Totalprice and Totalcost is the sum of all the items in each row of df1. Example: In the 2nd row, Totalprice is the sum of the price of items B, A, D and Totalcost is the sum of the cost of items B, A, D.
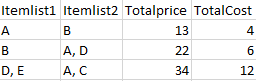
I am thinking of combining all the items into a column in df1, splitting each item into a column and then merging it with df2. This is what I have so far.
df1["items"]=df1[["Itemlist1","Itemlist2"]].agg(', '.join,axis=1)
df3=df1['items'].str.split(', ',expand=True)
As the number of items in each row is not fixed and the columns names also do not match, how can I loop this to merge with df2?
Alternatively, is there a better approach to arrive at the final df I want? Any suggestions please. Thank you.
CodePudding user response:
From your df3, do the replace, then sum with axis=1
cost_dict = dict(zip(df2.Itemcode,df2.Cost))
price_dict = dict(zip(df2.Itemcode,df2.Price))
df1['totalcost'] = df3.replace(cost_dict).sum(axis=1)
df1['totalprice'] = df3.replace(price_dict).sum(axis=1)