import pandas as pd #pandas working with tabular data as dataframes
from sklearn.model_selection import train_test_split #scikit-learn, building custom ML models
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression, RidgeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
#df = pd.read_csv('coords.csv')
#df = pd.read_csv('coords.csv', header=None)
#df = pd.read_csv('coords.csv', skiprows=[0])
df = pd.read_csv('coords.csv', skiprows=[0], header=None)
#df[df['class']=='Happy']
X = df.drop('class', axis=1) # features
y = df['class'] # target value
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1234)
pipelines = {
'lr':make_pipeline(StandardScaler(), LogisticRegression()),
'rc':make_pipeline(StandardScaler(), RidgeClassifier()),
'rf':make_pipeline(StandardScaler(), RandomForestClassifier()),
'gb':make_pipeline(StandardScaler(), GradientBoostingClassifier()),
}
fit_models = {}
for algo, pipeline in pipelines.items():
model = pipeline.fit(X_train, y_train)
fit_models[algo] = model
fit_models['rc'].predict(X_test)
df = pd.read_csv('coords.csv')
If I read the entire data array from the csv, the first row is also read and it gives an error when trying to convert a str to an int
Traceback (most recent call last):
File "3_Train_Custom_Model_Using_Scikit_Learn.py", line 71, in <module>
model = pipeline.fit(X_train, y_train)
ValueError: could not convert string to float: 'x1'
Then try various ways to remove that row containing the column names, which possibly generates the error. So considering that the indices start from 0, I did the following:
With df = pd.read_csv('coords.csv', skiprows=0), give me ValueError: could not convert string to float: 'x1'
And with
#df = pd.read_csv('coords.csv', header=None) #Option 1
#df = pd.read_csv('coords.csv', skiprows=[0], header=None) #Option 2
Give me this extrange error with pandas:
Traceback (most recent call last):
File "C:\Users\MyPC0\Anaconda3\lib\site-packages\pandas\core\indexes\base.py", line 3080, in get_loc
return self._engine.get_loc(casted_key)
File "pandas\_libs\index.pyx", line 70, in pandas._libs.index.IndexEngine.get_loc
File "pandas\_libs\index.pyx", line 98, in pandas._libs.index.IndexEngine.get_loc
File "pandas\_libs\index_class_helper.pxi", line 89, in pandas._libs.index.Int64Engine._check_type
KeyError: 'class'
I think that this pandas error is due to the fact that when omitting the row of column names associated with index 0, Pandas for some reason that I don't know tries to "find" the columns of that omitted row, and not being able to do it, it throws that error , which in the console looks like an exception from Pandas.
The "Pandas error" does not even indicate a line in the code, I have no idea what it could be, how could I solve it to be able to remove (though I'm really just skipping it) that line with the column names and be able to train the model with .fit ()?
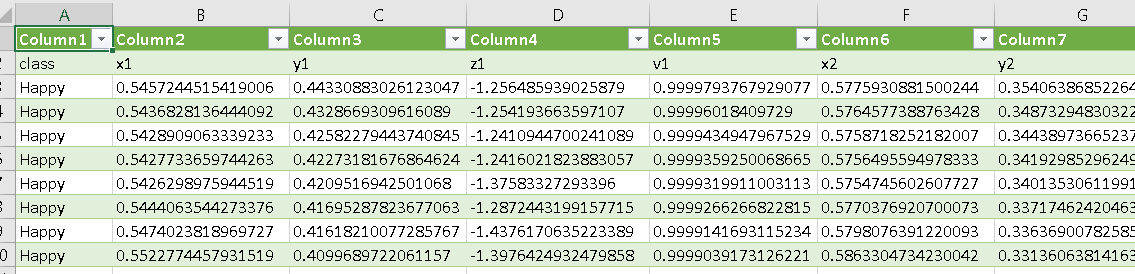
the csv file open in Excel
the csv file open in the text editor

I'm not sure if the problem could be the csv itself, although I doubt it. Anyway, here I leave the code of the algorithm that I use to load the data in the csv, taking the comma as a delimiter
pose = results.pose_landmarks.landmark
pose_row = list(np.array([[landmark.x, landmark.y, landmark.z, landmark.visibility] for landmark in pose]).flatten())
face = results.face_landmarks.landmark
face_row = list(np.array([[landmark.x, landmark.y, landmark.z, landmark.visibility] for landmark in face]).flatten())
row = pose_row face_row
row.insert(0, class_name)
with open('coords.csv', mode='a', newline='') as f:
csv_writer = csv.writer(f, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
csv_writer.writerow(row)
CodePudding user response:
By using answer from  You can see clearly the first column indicate the data separate properly and can assume this data have more than 1 row. So difference from your csv.
So you need to try
You can see clearly the first column indicate the data separate properly and can assume this data have more than 1 row. So difference from your csv.
So you need to try pandas to save your data. For example your pose, face data have n - pair data, the easy way to add all of the data is we can use loop to add to dict:
import pandas as pd
data_pose = {}
ind = 0
for landmark in pose:
data_pose['x' str(ind)] = landmark.x
data_pose['y' str(ind)] = landmark.y
data_pose['z' str(ind)] = landmark.z
data_pose['v' str(ind)] = landmark.visibility
ind = ind 1
data_face = {}
ind = 0
for landmark in face:
data_face['xx' str(ind)] = landmark.x
data_face['yy' str(ind)] = landmark.y
data_face['zz' str(ind)] = landmark.z
data_face['vv' str(ind)] = landmark.visibility
ind = ind 1
data = {**data_pose,**data_face}
df = pd.DataFrames(data)
df.to_csv('try.csv',sep=';')
And if you want to re-read csv file just do it like this :
df = pd.read_csv('try.csv',sep=';')
The header of df will be set default, in this case will take first row of your csv file. It will fix your ValueError: could not convert string to float: 'x1' error because this header will separate from your data.
Remember to make difference variable from pose and face, like x and xx.
But I prefer to use multiindex for this case.