I'm just starting to learn how to parse. From the website I need to get the names of the directions and the educational program (bachelor's degree, master's degree, etc...). But at the output I get only one element. Here is my code:
def get_HTML(url, params=None):
request = requests.get(url, headers=HEADERS, params = params) #params = get parameters
return request
def get_Content(html):
soup = BeautifulSoup(html, 'html.parser')
eduPrograms = soup.find_all('div', class_= 'column-center_rasp')
eduProgram = []
for i in eduPrograms:
eduProgram.append({
'title':i.find('div', class_='headerEduPrograms').get_text()
})
print(eduProgram)
eduDirection = soup.find_all('div', {'id': 'fak_id_7a3586aa7b32182f036c0dab143d2df8_493'})
eduDirections = []
for i in eduDirection:
eduDirections.append({
'title':i.find('div', class_='grpPeriod').get_text()
})
print(eduDirections)
def parse():
html = get_HTML(URL)
if (html.status_code) == 200:
get_Content(html.text)
else:
print('Error')
parse()
At the output I get only:
[{'title': 'Бакалавр'}] [{'title': '\n ИВТб-1301-04-00 '}]
HTML from site(only for a eduDirection)
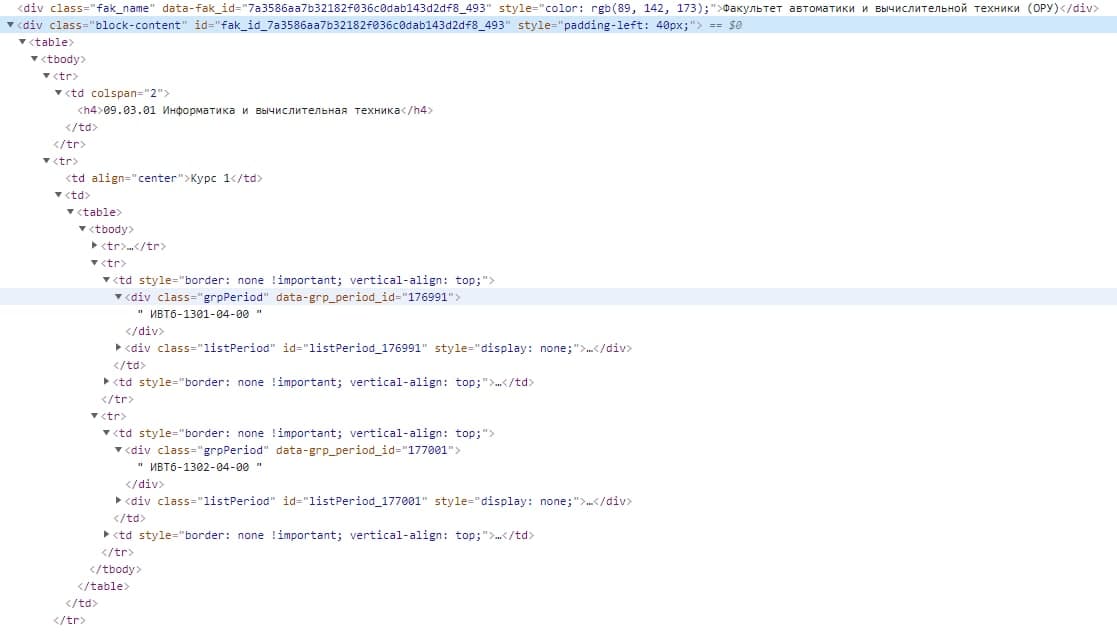
CodePudding user response:
eduDirection only has one match, there's no need to loop it.
In the loop, you're using i.find(), which just finds the first DIV with that class. You need to use .find_all() to find all of them.
eduDirection = soup.find('div', {'id': 'fak_id_7a3586aa7b32182f036c0dab143d2df8_493'})
eduDirections = [{'title': i.get_text()} for i in eduDirection.find_all('div', class_='grpPeriod')]
print(eduDirections)