The 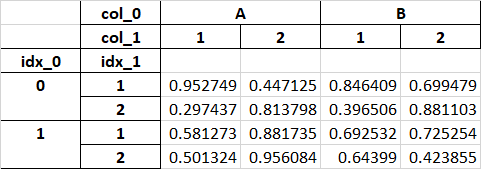
Aesthetics aside, the structure here is very clear, and indeed, the same as the structure in our df. Take notice of the merged cells especially.
Now, let's suppose we want to retrieve this data again from the Excel file at some later point, and we use pd.read_excel with default parameters. Problematically, we will end up with a complete mess:
df = pd.read_excel('file.xlsx')
print(df)
Unnamed: 0 col_0 A Unnamed: 3 B Unnamed: 5
0 NaN col_1 1.000000 2.000000 1.000000 2.000000
1 idx_0 idx_1 NaN NaN NaN NaN
2 0 1 0.952749 0.447125 0.846409 0.699479
3 NaN 2 0.297437 0.813798 0.396506 0.881103
4 1 1 0.581273 0.881735 0.692532 0.725254
5 NaN 2 0.501324 0.956084 0.643990 0.423855
Getting this data "back into shape" would be quite time-consuming. To avoid such a hassle, we can rely on the parameters index_col and header inside pd.read_excel:
df2 = pd.read_excel('file.xlsx', index_col=[0,1], header=[0,1])
print(df2)
col_0 A B
col_1 1 2 1 2
idx_0 idx_1
0 1 0.952749 0.447125 0.846409 0.699479
2 0.297437 0.813798 0.396506 0.881103
1 1 0.581273 0.881735 0.692532 0.725254
2 0.501324 0.956084 0.643990 0.423855
# check for equality
df.equals(df2)
# True
As you can see, we have made a "round trip" here, and index_col and header allow for it to have been smooth sailing!
Two final notes:
- (minor) The
docsforpd.read_excelcontain a typo in theindex_colsection: it should readmerge_cells=True, notmerged_cells=True. - The
headersection is missing a similar comment (or a reference to the comment atindex_col). This is somewhat confusing. As we saw above, the two behave exactly the same (for present purposes, at least).