I need to select from a table (user_id, i_id) only those values that match both user_ids.
Table structure
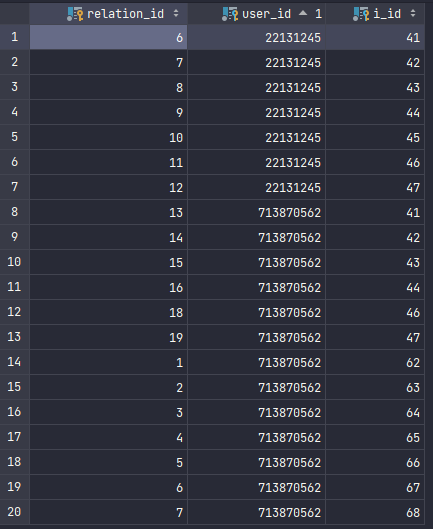
I tried to do it with SELECT DISTINCT, but it selects all the data
SELECT DISTINCT interest_relations.user_id, interest_relations.i_id
FROM interest_relations
WHERE interest_relations.user_id IN (713870562,22131245) GROUP BY user_id, i_id
I expect to get only those values that are the same for both users
CodePudding user response:
An alternative with inner join
select a.user_id user_a, b.user_id user_b, i_id
from interest_relations a join interest_relations b using (i_id)
where a.user_id < b.user_id;
| user_a | user_b | i_id |
|---|---|---|
| 22131245 | 713870562 | 41 |
| 22131245 | 715870562 | 42 |
| 22131245 | 713870562 | 43 |
| 22131245 | 715870562 | 44 |
| 22131245 | 713870562 | 46 |
| 22131245 | 713870562 | 47 |
CodePudding user response:
Select all user_id which have a count greater than 1:
SELECT *
FROM interest_relations
WHERE user_id IN (SELECT user_id
FROM interest_relations
GROUP BY user_id
HAVING count(*)>1)
see: DBFIDDLE
EDIT: After reading the answer from @stevanof-sm, I think I have mis-read the question. A simple query like next one may be all you need:
SELECT i_id, max(user_id) as "max", min(user_id) as "min"
FROM interest_relations
WHERE user_id in (22131245,715870562)
GROUP BY i_id;
output:
| i_id | max | min |
|---|---|---|
| 42 | 715870562 | 22131245 |
| 41 | 22131245 | 22131245 |
| 46 | 22131245 | 22131245 |
| 47 | 22131245 | 22131245 |
| 43 | 22131245 | 22131245 |
| 45 | 22131245 | 22131245 |
| 44 | 715870562 | 22131245 |