I have a pandas dataframe in the format below where JSON column is a JSON structure. The goal is to find a Schedule8812 key nested under in ReturnData key object in the JSON column. If a Schedule8812 key is found, it updates the Schedule8812 column to True for that row, and False otherwise.
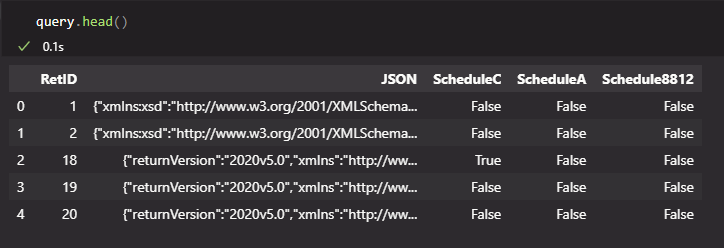
So far, I've been able to accomplish this by calling the function below.
import pyodbc
import json
from pprint import pprint
import pandas as pd
def iloc_df(df,col):
for i in df.index:
jdata=json.loads(df[col].iloc[i])
# print(jdata)
if 'Schedule8812' in jdata['ReturnData']:
df.at[i,'Schedule8812'] = True
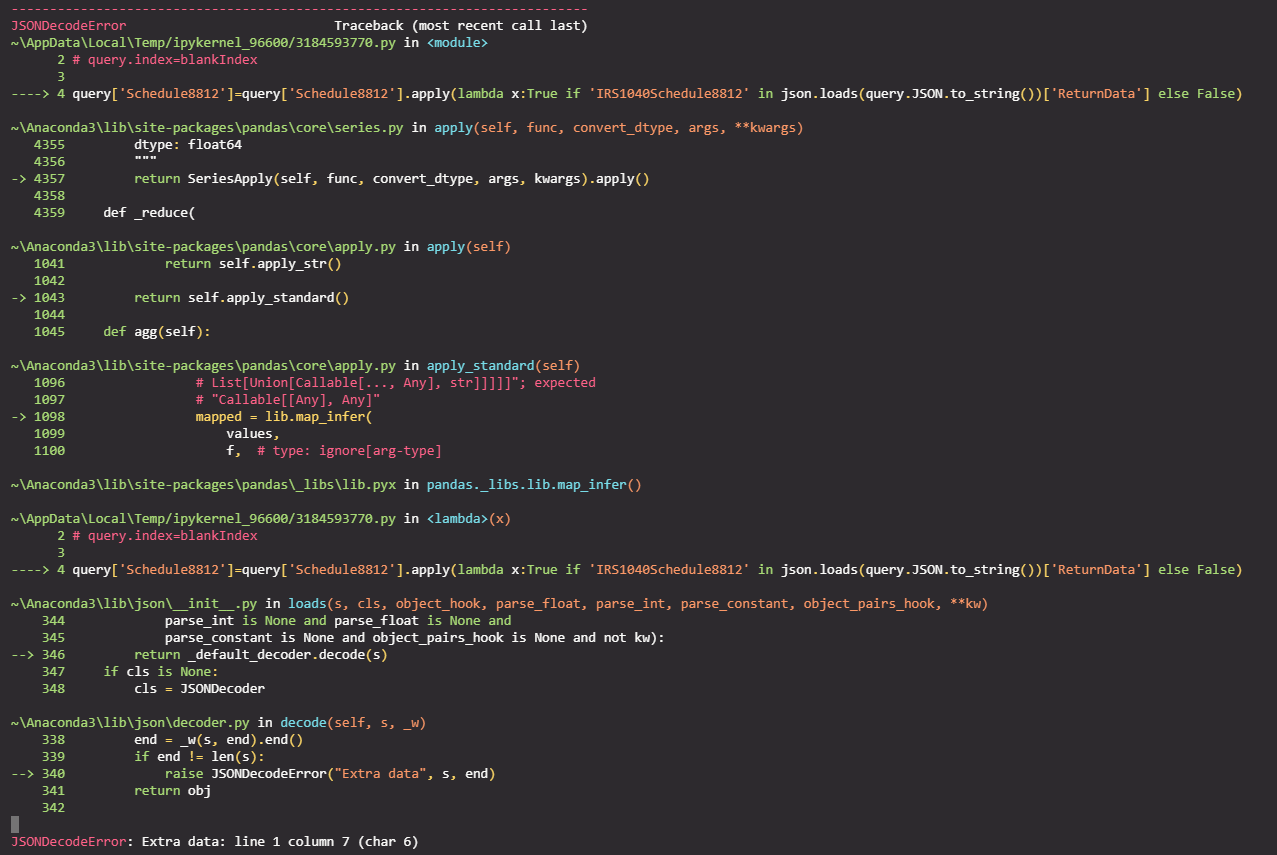
However, as the rows in my dataframe grows, the longer it completes. I'd like to switch it to a lambda expression but have been getting an error. Can someone point out to me a good reference on how to solve my lambda expression below thats getting an error?
query['Schedule8812']=query['Schedule8812'].apply(lambda x:True if 'Schedule8812' in json.loads(query.JSON.to_string())['ReturnData'] else False)
Below is the error I'm getting.
CodePudding user response:
You can test JSON column and in lambda use x instead query.JSON:
query['Schedule8812']=query['JSON'].apply(lambda x: 'Schedule8812' in json.loads(x.to_string())['ReturnData'])
Or if possible test subtring in column JSON use Series.str.contains:
query['Schedule8812']=query['JSON'].str.contains('Schedule8812')