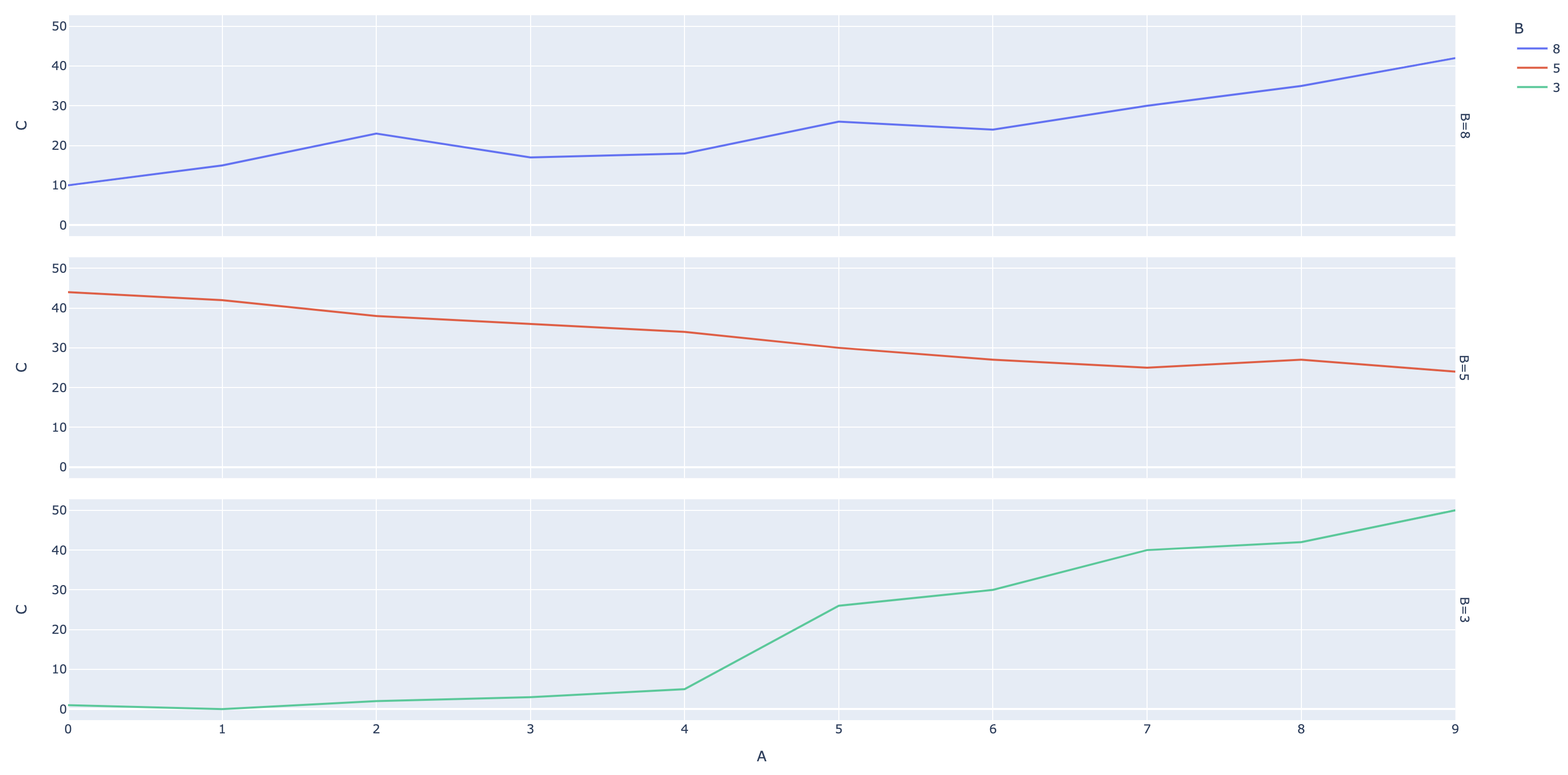
I have a dataframe which is much like the one following:
data = {'A':[21,22,23,24,25,26,27,28,29,30,11,12,13,14,15,16,17,18,19,20,1,2,3,4,5,6,7,8,9,10],
'B':[8,8,8,8,8,8,8,8,8,8,5,5,5,5,5,5,5,5,5,5,3,3,3,3,3,3,3,3,3,3],
'C':[10,15,23,17,18,26,24,30,35,42,44,42,38,36,34,30,27,25,27,24,1,0,2,3,5,26,30,40,42,50]}
data_df = pd.DataFrame(data)
data_df
I would like to have the subplots, the number of subplots should be equal to number of unique values of column 'B'. X axis = Values in column 'A' and Y axis = values in Column 'C'.
The code that I tried:
fig = px.line(data_df,
x='A',
y='C',
color='B',
facet_col = 'B',
)
fig.show()
gives output like
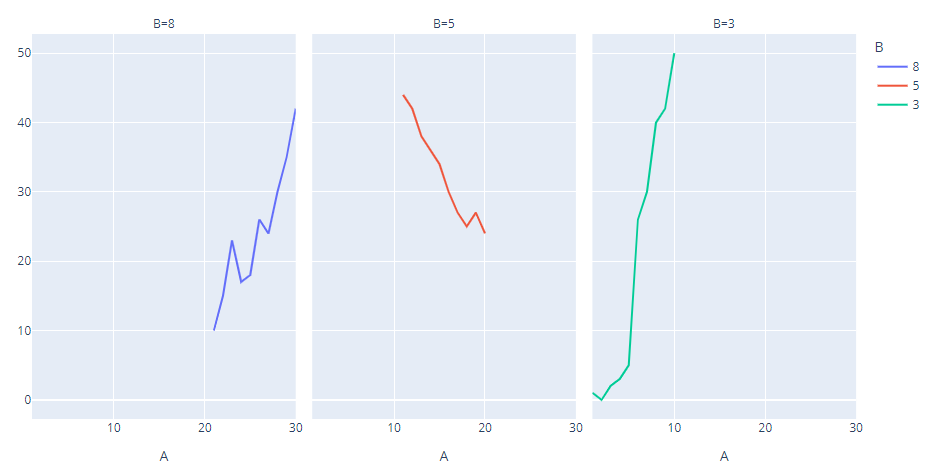
However, I would like to have the graphs in a single column, each graph autoscaled to the relevant area and resolution on the axes. Possibility: Can I somehow make use of groupby command to do it?
Since I may have other number of unique values in column 'B' (for example 5 unique values) based on other data, I would like to have this piece of code to work dynamic. Kindly help me.
PS: plotly express module is used to plot the graph.
CodePudding user response:
In order to stack all subplot in one column, and make sure that each xaxis is independent, just add the following in your px.line() call:
facet_col_wrap=1
And then follow up with:
fig.update_xaxes(matches=None)
Plot 1
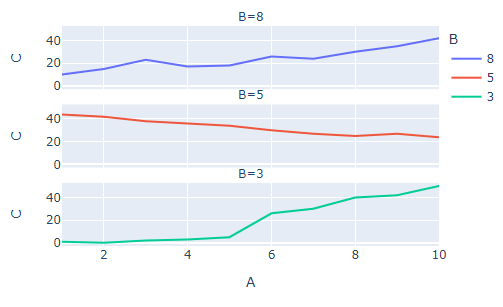
Complete code:
import plotly.express as px
import pandas as pd
data = {'A':[21,22,23,24,25,26,27,28,29,30,11,12,13,14,15,16,17,18,19,20,1,2,3,4,5,6,7,8,9,10],
'B':[8,8,8,8,8,8,8,8,8,8,5,5,5,5,5,5,5,5,5,5,3,3,3,3,3,3,3,3,3,3],
'C':[10,15,23,17,18,26,24,30,35,42,44,42,38,36,34,30,27,25,27,24,1,0,2,3,5,26,30,40,42,50]}
data_df = pd.DataFrame(data)
data_df
fig = px.line(data_df,
x='A',
y='C',
color='B',
facet_col = 'B',
facet_col_wrap=1
)
fig.update_xaxes(matches=None)
fig.show()
CodePudding user response:
You can instead use the argument facet_row = 'B' which will automatically stack the subplots by rows. Then to automatically rescale, you'll want to set all of the x data to the same array of values, which can be done by looping through fig.data and modifying fig.data[i]['x'] for each i.
import pandas as pd
import plotly.express as px
data = {'A':[21,22,23,24,25,26,27,28,29,30,11,12,13,14,15,16,17,18,19,20,1,2,3,4,5,6,7,8,9,10],
'B':[8,8,8,8,8,8,8,8,8,8,5,5,5,5,5,5,5,5,5,5,3,3,3,3,3,3,3,3,3,3],
'C':[10,15,23,17,18,26,24,30,35,42,44,42,38,36,34,30,27,25,27,24,1,0,2,3,5,26,30,40,42,50]}
data_df = pd.DataFrame(data)
fig = px.line(data_df,
x='A',
y='C',
color='B',
facet_row = 'B',
)
for fig_data in fig.data:
fig_data['x'] = list(range(len(fig_data['y'])))
fig.show()