I'm creating a Deep Neural Network for linear regression. The net has 3 hidden layers with 256 units per layer. Here is the model:
Each unit has ReLU as activation function. I also used Early Stopping to make sure it doesn't overfit.
The target is an integer and in the training set its values goes from 0 to 7860.
After the training i've got the following losses:
train_MSE = 33640.5703, train_MAD = 112.6294,
val_MSE = 53932.8125, val_MAD = 138.7836,
test_MSE = 52595.9414, test_MAD= 137.2564
I've tried many different configurations of the net (different optimizer, loss functions, normalizations, regularizers...) but nothing seems to help me to reduce the loss even further. Even if the training error decrease, the test error never goes under a value of MAD = 130.
Here's the behavior of my net: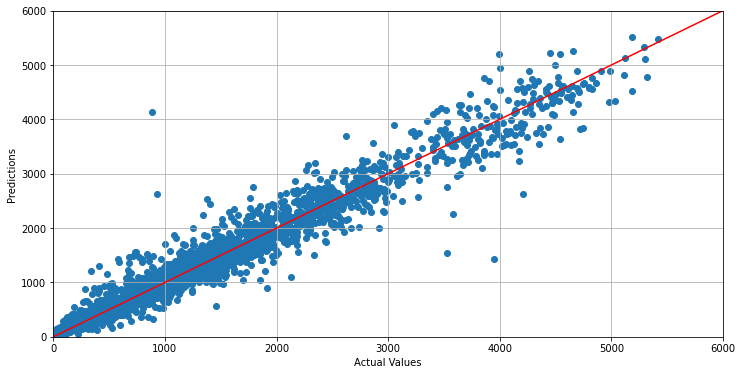
My question is if there's a way to improve my dnn to make more accurate predictions or this is the best that i can achieve with my dataset?
CodePudding user response:
If your problem is linear by nature, meaning the real function behind your data is of the from: y = a*x b epsilon where the last term is just random noise.
You won't get any better than fitting the underlying function y = a*x b. Fitting espilon would only result in loss of generalization over new data.
CodePudding user response:
You can try a many different things to improve DNN,
- Increase hidden layers
- Scale or Normalize your data
- Try rectified linear unit as Activation
- Take More data
- Change learning algorithm parameters like learning rates