I have this beer dataset that I've been trying to clean as a personal project for quite some time, but I can't seem to get past a couple of hiccups.
I have this "list of uneven lists" I guess you would call it, that I need to organize. Here is a brief example of what I'm looking at: [updated to add form of data]
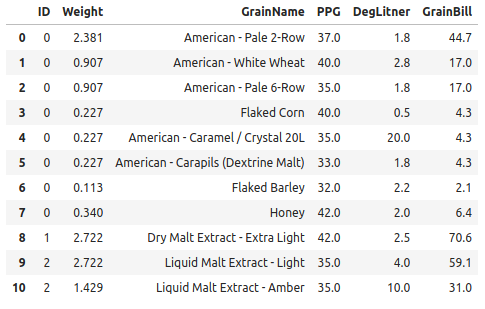
data = [[2.3810000000000002, 'American - Pale 2-Row', 37.0, 1.8, 44.7], [0.907, 'American - White Wheat', 40.0, 2.8, 17.0], [0.907, 'American - Pale 6-Row', 35.0, 1.8, 17.0], [0.227, 'Flaked Corn', 40.0, 0.5, 4.3], [0.227, 'American - Caramel / Crystal 20L', 35.0, 20.0, 4.3], [0.227, 'American - Carapils (Dextrine Malt)', 33.0, 1.8, 4.3], [0.113, 'Flaked Barley', 32.0, 2.2, 2.1], [0.34, 'Honey', 42.0, 2.0, 6.4]],[[2.722, 'Dry Malt Extract - Extra Light', 42.0, 2.5, 70.6],[[2.722, 'Liquid Malt Extract - Light', 35.0, 4.0, 59.1], [1.429, 'Liquid Malt Extract - Amber', 35.0, 10.0, 31.0]]]
So for column 0, which would relate to a beer called Vanilla Cream Ale, is a list of multiple lists that contain 5 parameters.
[[2.3810000000000002, 'American - Pale 2-Row', 37.0, 1.8, 44.7], [0.907, 'American - White Wheat', 40.0, 2.8, 17.0], [0.907, 'American - Pale 6-Row', 35.0, 1.8, 17.0], [0.227, 'Flaked Corn', 40.0, 0.5, 4.3], [0.227, 'American - Caramel / Crystal 20L', 35.0, 20.0, 4.3], [0.227, 'American - Carapils (Dextrine Malt)', 33.0, 1.8, 4.3], [0.113, 'Flaked Barley', 32.0, 2.2, 2.1], [0.34, 'Honey', 42.0, 2.0, 6.4]]
For column 1 I have
[[2.722, 'Dry Malt Extract - Extra Light', 42.0, 2.5, 70.6]]
2 is
[[2.722, 'Liquid Malt Extract - Light', 35.0, 4.0, 59.1], [1.429, 'Liquid Malt Extract - Amber', 35.0, 10.0, 31.0]]
Where each element is each element is 'weight', 'grain_name', 'ppg', 'deg_litner', 'grain_bill'. So far, I have been able to separate out the weights, grain names, etc out of the lists into individual lists that I can call.
I'd like to end up having an ID, where 0 corresponds to Vanilla Cream ale with each of these elements being listed. I imagine '0' would be repeated eight times, '1' one times, and '2' two times, but I'm not sure that is the best approach.
I've managed to make a list that counted the number of lists in each element:
fcount = [8,1,2]
I was thinking I could do something like
for i in range(0,3):
[i] * fcount
thinking I could get
[0,0,0,0,0,0,0,0]
[1]
[2,2]
but you apparently can't multiply a list like that.
I'm having a really hard time finding the best approach overall, and I'm not sure this is the right way - but it's SOME way, I suppose. My overall goal is to complete a relational database in SQL Server - I have all the beer data in there (ibu, abv, etc), it's just missing this mess! Thanks for any help with this!
CodePudding user response:
What you refer to as a "uneven lists" is a "tuple" or a "row". And a set of tuples/rows with the same shape is called a "relation" or a "table".
Where each element is each element is 'weight', 'grain_name', 'ppg', 'deg_litner', 'grain_bill'
In SQL Server you would create tables like
create table Beers
(
BeerId int identity primary key,
BeerName varchar(200),
ABV decimal(2,2)
)
create table BeerIngredients
(
BeerId int not null referencess Beer(BeerId),
BeerIngredientId int identity not null,
Weight decimal(10,2),
GrainName varchar(200),
PPG decimal(10,2),
DegLitner decimal(10,2),
GrainBill decimal(10,2),
constraint pk_BeerIngredients
primary key (BeerName,BeerIngredientId)
)
And which you could load into a pandas table to work with in Python, something like this:
import pandas
import pyodbc
import sqlalchemy
data = [[2.3810000000000002, 'American - Pale 2-Row', 37.0, 1.8, 44.7],
[0.907, 'American - White Wheat', 40.0, 2.8, 17.0],
[0.907, 'American - Pale 6-Row', 35.0, 1.8, 17.0],
[0.227, 'Flaked Corn', 40.0, 0.5, 4.3],
[0.227, 'American - Caramel / Crystal 20L', 35.0, 20.0, 4.3],
[0.227, 'American - Carapils (Dextrine Malt)', 33.0, 1.8, 4.3],
[0.113, 'Flaked Barley', 32.0, 2.2, 2.1],
[0.34, 'Honey', 42.0, 2.0, 6.4],
[2.722, 'Dry Malt Extract - Extra Light', 42.0, 2.5, 70.6]]
df = pandas.DataFrame(data, columns=['Weight','GrainName','PPG','DegLitner','GrainBill'])
print(df)
engine = sqlalchemy.create_engine('mssql pyodbc://localhost/tempdb?trusted_connection=yes&driver=ODBC Driver 17 for SQL Server')
df.to_sql('BeerIngredients',engine, index=False,if_exists='replace')
CodePudding user response:
Here is a solution if I'm understanding correctly. Given the following input data
data = [[
[2.3810000000000002, 'American - Pale 2-Row', 37.0, 1.8, 44.7],
[0.907, 'American - White Wheat', 40.0, 2.8, 17.0],
[0.907, 'American - Pale 6-Row', 35.0, 1.8, 17.0],
[0.227, 'Flaked Corn', 40.0, 0.5, 4.3],
[0.227, 'American - Caramel / Crystal 20L', 35.0, 20.0, 4.3],
[0.227, 'American - Carapils (Dextrine Malt)', 33.0, 1.8, 4.3],
[0.113, 'Flaked Barley', 32.0, 2.2, 2.1],
[0.34, 'Honey', 42.0, 2.0, 6.4]
],
[
[2.722, 'Dry Malt Extract - Extra Light', 42.0, 2.5, 70.6]
],
[
[2.722, 'Liquid Malt Extract - Light', 35.0, 4.0, 59.1],
[1.429, 'Liquid Malt Extract - Amber', 35.0, 10.0, 31.0]
]
]
loop through the outer most list and get the index of each element using enumerate. Then, loop through each inner list, prepend the index to each of the 5 element lists and combine them into one main list, data_id, and finally convert the main list into a dataframe that can be written to the database, as described in @David Browne - Microsoft's answer:
import pandas as pd
data_id = []
for ind, d in enumerate(data):
for a in d:
a.insert(0, ind)
data_id.append(a)
df.columns = ['ID', 'Weight', 'GrainName', 'PPG', 'DegLitner', 'GrainBill']
df = pd.DataFrame(data_id)
Output: