This is a purely fictional example, but it demonstrates what I need. My current code that gets the results I want, but I would like to write a nested for loop to create lists / dataframes automatically without hard coding (or whatever can reduce hard-coding).
In this case, I have data that has columns for Age Group and Gender. I want to create a stacked barchart with Plotly for each Age Group, broken down by Gender. Also, I'm using pandas to massage the data.
The problem I'm having is that either Age Group and Gender could change. For example, the current data set has Age Groups: 20s, 30s, 40s, 50s, 60s, 70s, 80s, 90 , but other age groups can be added in the future (90s, 100s, 110s, etc.) so I would have to go back and add these in manually.
Similarly, the current data set has genders: female, male, unspecified, but other categories can be added in the future. If a new gender category is added, I would have to go back into the code and add it in manually as well.
import plotly.offline as pyo
import plotly.graph_objs as go
import pandas as pd
# source = "https://data.ontario.ca/dataset/f4112442-bdc8-45d2-be3c-12efae72fb27/resource/455fd63b-603d-4608-8216-7d8647f43350/download/conposcovidloc.csv"
df = pd.read_csv("conposcovidloc.csv")
# Age_Group = ['<20', '20s', '30s', '40s', '50s', '60s', '70s','80s', '90 ', 'UNKNOWN']
Age_Group = df["Age_Group"].unique().tolist()
# Client_Gender = df["Client_Gender"].unique().tolist()
count_female = []
count_male = []
count_unspecified = []
count_diverse = []
for age in Age_Group:
count_female.append(df[(df["Age_Group"]==age) & (df["Client_Gender"]=="FEMALE")]["Age_Group"].count())
count_male.append(df[(df["Age_Group"]==age) & (df["Client_Gender"]=="MALE")]["Age_Group"].count())
count_unspecified.append(df[(df["Age_Group"]==age) & (df["Client_Gender"]=="UNSPECIFIED")]["Age_Group"].count())
count_diverse.append(df[(df["Age_Group"]==age) & (df["Client_Gender"]=="GENDER DIVERSE")]["Age_Group"].count())
trace1 = go.Bar(x=Age_Group, y=count_female, name="Female", marker={"color": "#FFD700"})
trace2 = go.Bar(x=Age_Group, y=count_male, name="Male", marker={"color": "#9EA0A1"})
trace3 = go.Bar(x=Age_Group, y=count_unspecified, name="Unspecified", marker={"color": "#CD7F32"})
trace4 = go.Bar(x=Age_Group, y=count_diverse, name="Gender Diverse", marker={"color": "#000000"})
data = [trace1, trace2, trace3, trace4]
layout = go.Layout(title="Ontario COVID-19 Case Breakdown by Age Group and Gender", barmode="stack")
fig = go.Figure(data=data, layout=layout)
pyo.plot(fig, filename="bar.html")
I was thinking maybe doing something like this to get a new dataframe
df2 = []
for age in Age_Group:
for gender in Client_Gender:
count_female.append(df[(df["Age_Group"]==age) & (df["Client_Gender"]==gender)]["Age_Group"].count())
df2.append()
trace = go.Bar(x=Age_Group, y=Client_Gender, name=Client_Gender)
Maybe I'm approaching this the wrong way completely.
Edit: I've almost got it, thanks to @samir-hinojosa with the advice of using globals(). Here's my revised code that is almost what what I need. My for loop looks like its being replicated multiple times, and I'm not sure why.
import plotly.offline as pyo
import plotly.graph_objs as go
import pandas as pd
url = "https://data.ontario.ca/dataset/f4112442-bdc8-45d2-be3c-12efae72fb27/resource/455fd63b-603d-4608-8216-7d8647f43350/download/conposcovidloc.csv"
df = pd.read_csv(url)
Age_Group = df["Age_Group"].unique().tolist()
Client_Gender = df["Client_Gender"].unique().tolist()
data = []
for gender in df["Client_Gender"].unique():
globals()["count_" gender] = []
for gender in Client_Gender:
for age in Age_Group:
globals()["count_" gender].append(df[(df["Age_Group"]==age) & (df["Client_Gender"]==gender)]["Client_Gender"].count())
trace = go.Bar(x=Age_Group, y=globals()["count_" gender], name=gender)
data.append(trace)
layout = go.Layout(title="Ontario COVID-19 Case Breakdown by Age Group and Gender") # Remove barmode to get nested
fig = go.Figure(data=data, layout=layout)
pyo.plot(fig, filename="html/bar.html")
The numbers and shape of the chart look correct, but the legend shows gender multiple times, not sure how to fix this. There should only be 4 genders in the legend.
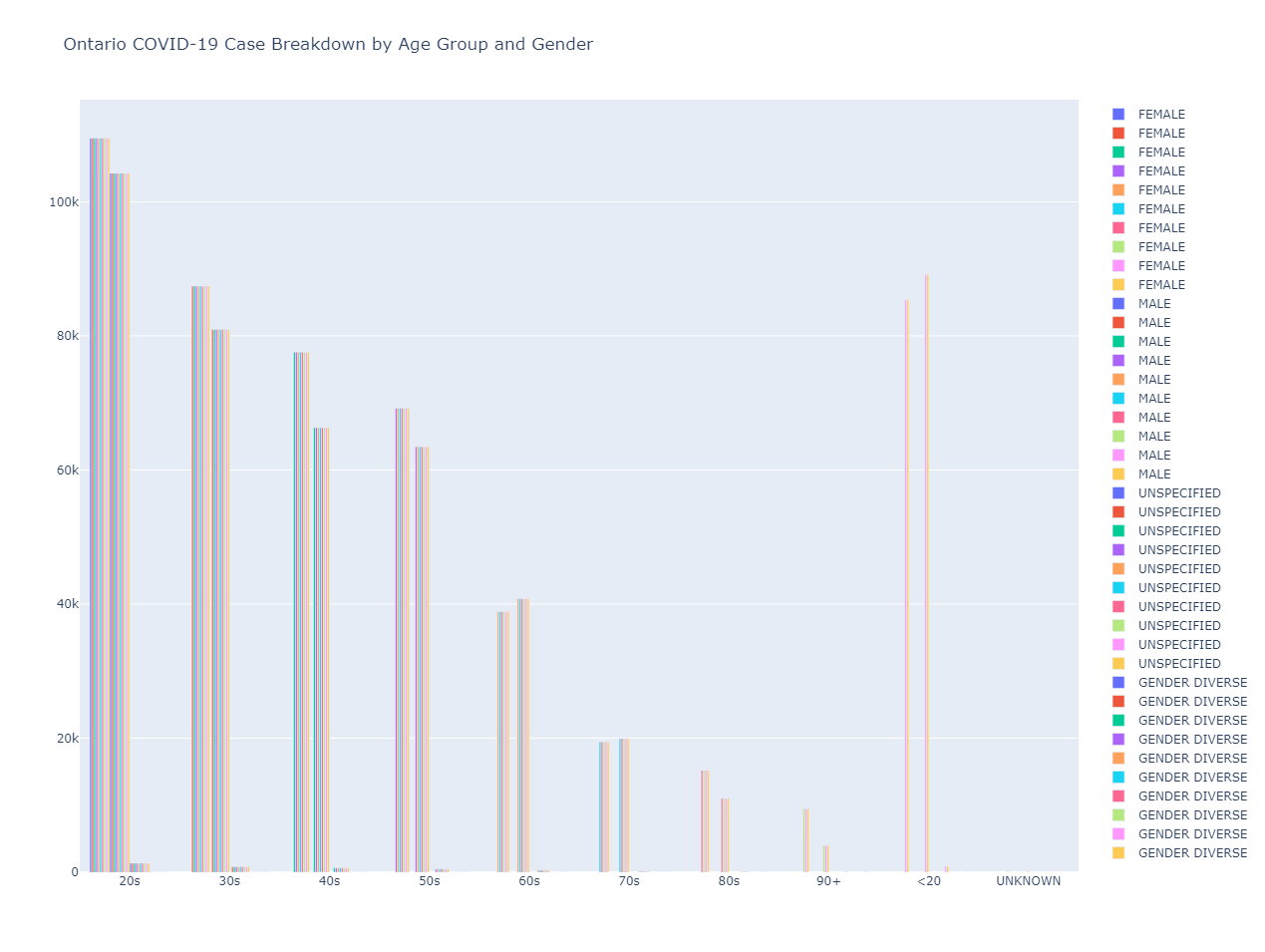
CodePudding user response:
You can use globals(). You can see an example below
import pandas as pd
url = "https://raw.githubusercontent.com/alexisperrier/intro2nlp/master/data/openclassrooms_intro2nlp_sentiment_vegetables.csv"
df = pd.read_csv(url)
df.head()
tweet_id search_keyword sentiment text neg pos
0 1340355010299908096 parsnip 1 @user @user All the best @user you cheeky litt... 0.009569 0.874337
1 1340093851143450624 green beans 1 RT @user @user lamb chops , green beans , maca... 0.001479 0.966661
2 1340089889984012290 eggplant 1 @user I make the best eggplant parmesan 0.002113 0.955990
3 1340053955792035840 yams 0 They candied yams go stupid! 0.918229 0.011744
4 1339085046548897792 spinach 0 @user Cooked spinach. Just kidding that stuff ... 0.871717 0.014765
df["search_keyword"].unique()
array(['parsnip', 'green beans', 'eggplant', 'yams', 'spinach', 'celery',
'leek', 'carrot', 'tomato', 'chickpea', 'avocado', 'asparagus',
'mushroom', 'cabbage', 'kale', 'lettuce', 'quinoa', 'potato',
'onion', 'cucumber', 'rice', 'cauliflower', 'brocolli', 'turnip',
'lentils', 'pumpkin', 'corn', 'okra', 'radish', 'artichoke',
'squash', 'garlic', 'endive', 'zuchinni'], dtype=object)
In this case, I am going to create dinamically several dataframe based on the search_keyword list
for search_keyword in df["search_keyword"].unique():
globals()["df_" search_keyword] = df[df["search_keyword"]==search_keyword]
Now, you can access each dataframe based on the name "df_" df["search_keyword"].unique()
df_eggplant.head()
tweet_id search_keyword sentiment text neg pos
2 1340089889984012290 eggplant 1 @user I make the best eggplant parmesan 0.002113 0.955990
33 1340284341449076736 eggplant 1 Just guys no the later today? only using a bit... 0.009440 0.838516
62 1338954692173258753 eggplant 1 @user Oh wow, lucky eggplant! 0.003778 0.946546
182 1338889204575526919 eggplant 0 RT @user destyal hotfuck 27cm.