I try to achieve performance improvement and made some good experience with SIMD. So far I was using OMP and like to improve my skills further using intrinsics.
In the following scenario, I failed to improve (even vectorize) due to a data dependency of a last_value required for a test of element n 1.
Environment is x64 having AVX2, so want to find a way to vectorize and SIMDfy a function like this.
inline static size_t get_indices_branched(size_t* _vResultIndices, size_t _size, const int8_t* _data) {
size_t index = 0;
int8_t last_value = 0;
for (size_t i = 0; i < _size; i) {
if ((_data[i] != 0) && (_data[i] != last_value)) {
// add to _vResultIndices
_vResultIndices[index] = i;
last_value = _data[i];
index;
}
}
return index;
}
Input is an array of signed 1-byte values. Each element is one of <0,1,-1>. Output is an array of indices to input values (or pointers), signalling a change to 1 or -1.
example in/output
in: { 0,0,1,0,1,1,-1,1, 0,-1,-1,1,0,0,1,1, 1,0,-1,0,0,0,0,0, 0,1,1,1,-1,-1,0,0, ... }
out { 2,6,7,9,11,18,25,28, ... }
My first attempt was, to play with various branchless versions and see, if auto vectorization or OMP were able to translate it into a SIMDish code, by comparing assembly outputs.
example attempt
int8_t* rgLast = (int8_t*)alloca((_size 1) * sizeof(int8_t));
rgLast[0] = 0;
#pragma omp simd safelen(1)
for (size_t i = 0; i < _size; i) {
bool b = (_data[i] != 0) & (_data[i] != rgLast[i]);
_vResultIndices[index] = i;
rgLast[i 1] = (b * _data[i]) (!b * rgLast[i]);
index = b;
}
Since no experiment resulted in SIMD output, I started to experiment with intrinsics with the goal to translate the conditional part into a mask.
For the != 0 part that's pretty straight forward:
__m256i* vData = (__m256i*)(_data);
__m256i vHasSignal = _mm256_cmpeq_epi8(vData[i], _mm256_set1_epi8(0)); // elmiminate 0's
The conditional aspect to test against "last flip" I found not yet a way.
To solve the following output packing aspect I assume 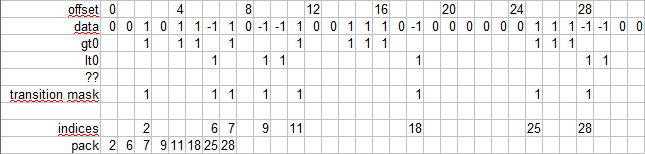 The challenge now is how to create the transition mask based on gt0 and lt0 masks.
The challenge now is how to create the transition mask based on gt0 and lt0 masks.
CodePudding user response:
Complete vectorization is suboptimal for your case. It’s technically possible, but I think the overhead of producing that array of uint64_t values (I assume you’re compiling for 64 bit CPUs) will eat all the profit.
Instead, you should load chunks of 32 bytes, and immediately convert them to bit masks. Here’s how:
inline void loadBits( const int8_t* rsi, uint32_t& lt, uint32_t& gt )
{
const __m256i vec = _mm256_loadu_si256( ( const __m256i* )rsi );
lt = (uint32_t)_mm256_movemask_epi8( vec );
const __m256i cmp = _mm256_cmpgt_epi8( vec, _mm256_setzero_si256() );
gt = (uint32_t)_mm256_movemask_epi8( cmp );
}
The rest of your code should deal with these bitmaps. To find first non-zero element (you only need to do that at the start of your data), scan for least significant set bit in (lt | gt) integer. To find -1 number, scan for least significant set bit in lt integer, to find 1 number scan for least significant set bit in gt integer. Once found and handled, you can either clear low portion of both integers with bitwise AND, or shift them both to the right.
CPUs have BSF instruction which scans for the lowest set bit in an integer, and returns two things at once: a flag telling if the integer was zero, and the index of that set bit. If you’re using VC there’s _BitScanForward intrinsic, otherwise use inline ASM, that instruction is only exposed in VC ; GCC’s __builtin_ctz is not quite the same thing, it only returns a single value instead of two.
However, on AMD CPUs, the TZCNT instruction from BMI 1 set is somewhat faster than the old-school BSF (on Intel they’re equal). On AMD, TZCNT will probably be slightly faster, despite the extra instruction to compare with 0.