I am learning web scraping using rvest. The goal is to get the href property of
<a href="#!Synapse:syn21656973">docker.synapse.org/syn21654780/normcorr</a> from this 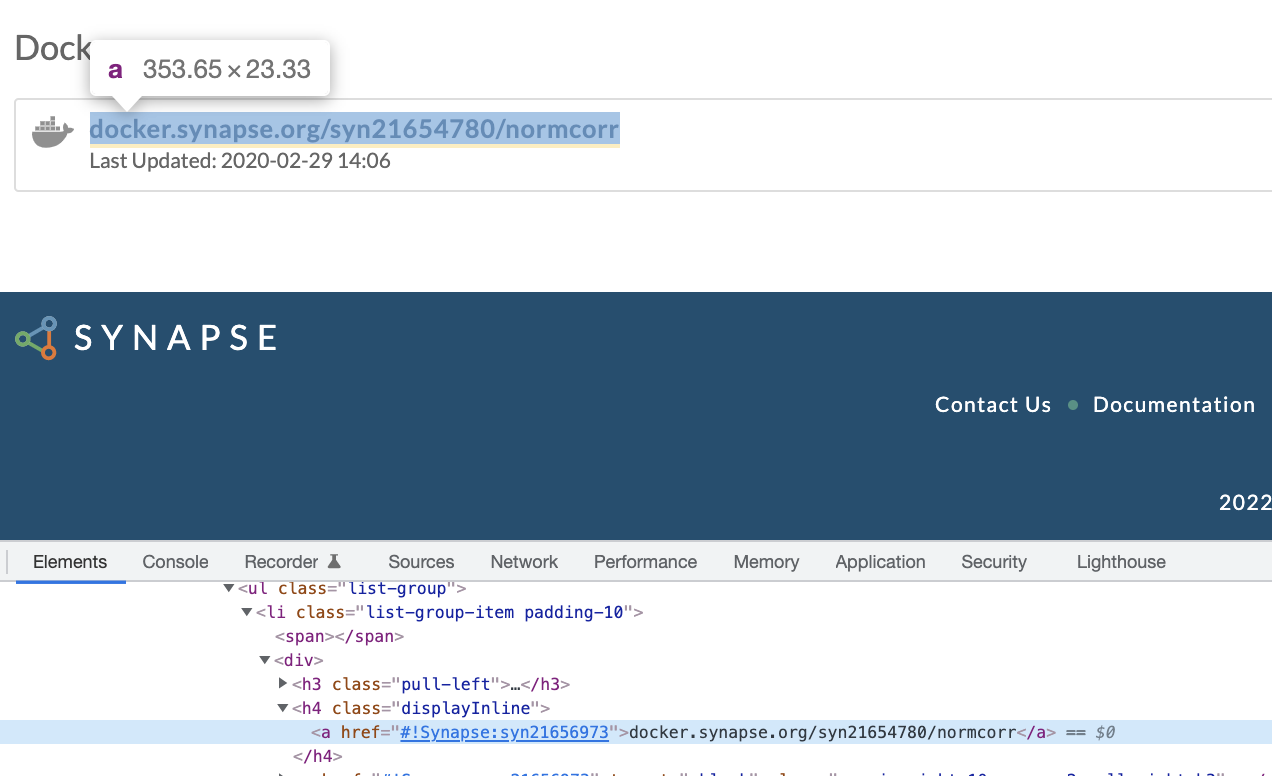
I tried to use a R package, rvest:
pg <- "https://www.synapse.org/#!Synapse:syn21654780/docker/"
pg %>% read_html() %>%
html_nodes(".displayInline, a") %>%
html_attr("href")
# I can only some get:
"https://synapse.prod.sagebase.org/Portal.html#!Home:0"
Expected Result:
"#!Synapse:syn21656973"
How to retrieve the href from <a> select? Please feel free to use Python if needed.
CodePudding user response:
You can read the anchor text and then construct the url on your own.
First the the username from the subdomain and then id from upcoming part of the text of the anchor
docker.<username_here>.com/<id_here>/remainingtetxt.
just construct <username_here>/<id_here>
CodePudding user response:
A RSelenium solution,
#start browser
library(dplyr)
library(rvest)
library(RSelenium)
browser = c("firefox"))
remDr <- driver[["client"]]
#navigate
url <- 'https://www.synapse.org/#!Synapse:syn21654780/docker/'
remDr$navigate(url)
#get the links
remDr$getPageSource()[[1]] %>%
read_html() %>% html_nodes('.displayInline') %>% html_nodes('a') %>%
html_attr('href')
[1] "#!Synapse:syn21654780/wiki/" "#!Synapse:syn21654780/files/" "#!Synapse:syn21654780/datasets/" "#!Synapse:syn21654780/tables/"
[5] "#!Synapse:syn21654780/challenge/" "#!Synapse:syn21654780/discussion/" "#!Synapse:syn21654780/docker/" "#!Synapse:syn21656973"