I wanted to create a dictionary where I would pull the holdings as the key along with the Weight(%) as the value. But when I try to use soup.find('table', {'id' : 'etf_holding_table'}) to access the table, nothing shows up. I saw some posts saying that it might be inside a comment and tried to copy a few ways things were done there, but I wasn't able to do so successfully.
I ended up finding someone's response to a way to pull ticker information using re, but I can't seem to find any good resources explaining what his code was doing.
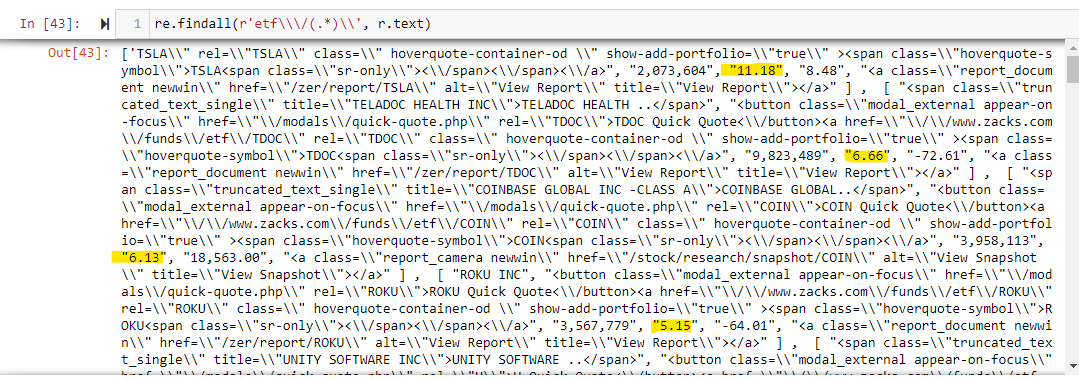
I'd very much appreciate some good resources on understanding and using re as I clearly don't understand too well what I'm doing, or how to get the information I need. I would message the poster I got the code from, but it seems as though you can't message someone on Stack Overflow.
CodePudding user response:
The data is contained inside a "javascript variable" etf_holdings.formatted_data
<script>
var etf_holdings = {};
etf_holdings.formatted_data = [ [ "TESLA INC", ...
This is processed by javascript in your browswer and turned into the table you see.
When you fetch the raw html with requests - you're not executing javascript - which is why the table is "not there" when you try to find it with BeautifulSoup.
One way of isolating the line containing the data:
>>> import json, requests
>>> r = requests.get('https://www.zacks.com/funds/etf/ARKK/holding', headers={'User-Agent': ''})
>>> line = next(line for line in r.text.splitlines() if line.startswith('etf_holdings.formatted_data '))
If we keep the [ [ .... ] ] i.e. remove everything before the first = and chop off the trailing semicolon - we can load this using the json module.
>>> line[:40]
'etf_holdings.formatted_data = [ [ "TESLA'
>>> line[-10:]
'</a>" ] ];'
.find() and slicing is one way to do this:
>>> line = line[line.find('= ') 2:-1]
>>> data = json.loads(line)
>>> len(data)
45
Each item is the raw data used to create a row in table:
>>> data[0]
['TESLA INC',
'<button
href="/modals/quick-quote.php" rel="TSLA">TSLA Quick Quote</button>
<a href="//www.zacks.com/funds/etf/TSLA" rel="TSLA"
show-add-portfolio="true" >
<span >TSLA<span ></span></span></a>',
'2,073,604',
'11.18',
'8.48',
'<a
href="/zer/report/TSLA" alt="View Report" title="View Report"></a>']
CodePudding user response:
So, as already pointed out, the data is within a different JavaScript variable within the response.
I would therefore alter the regex to pick up that entire JavaScript array object, then pass that to json library to extract the desired info.
The regex would be:
etf_holdings\.formatted_data = (\[.*?\]);
That is matching as follows:
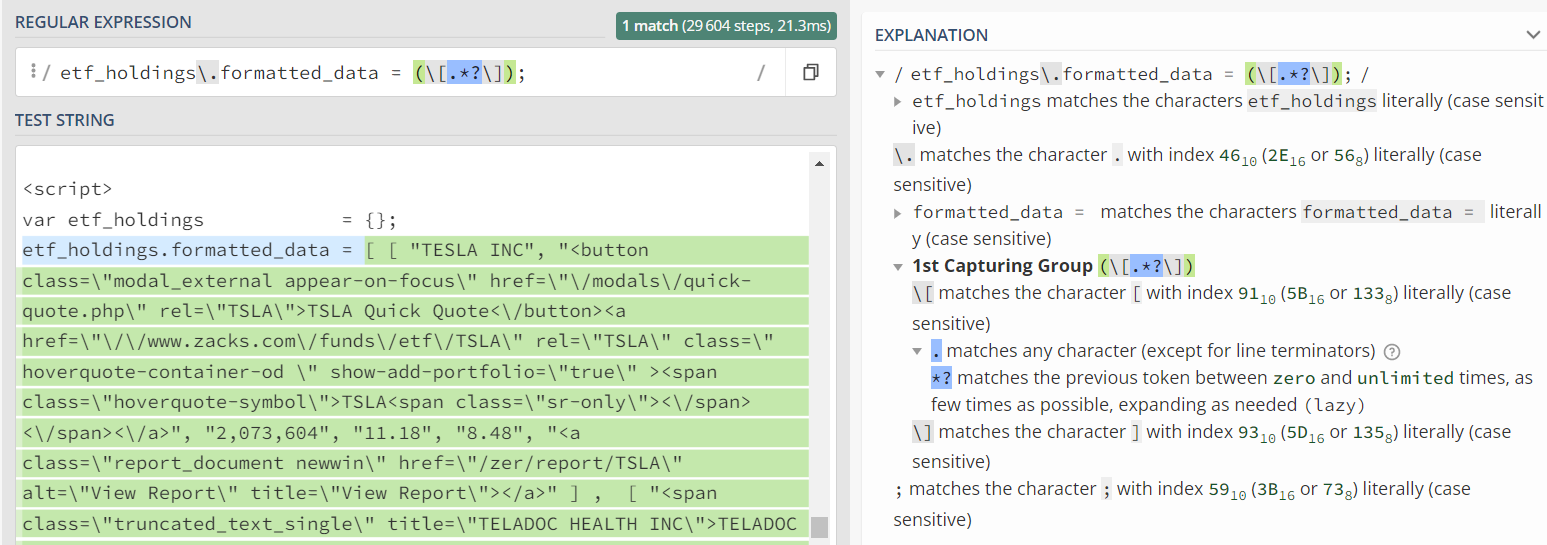
Compile this pattern in advance for efficiency of re-use.
Use .search() to match anywhere in string then extract the first match group.
Parse the extracted group with json and you get a list of lists as follows:

Note that the data you want is contained at indices 1 and 3 of each list within the parent list. Index 1 is html you can parse with BeautifulSoup to get the desired symbol, and index 3 can be directly extracted. For some items there is no symbol/associated weight value:

As this could lead to the same key being parse out during scraping, with no meaning in final dictionary, I simply exclude these items by testing whether rel=" is present in index 1 string. This is to avoid parsing twice the html within the list comprehension. I make an assumption, based on examining the index 1 strings, as aforementioned, and that these are highly specific short strings, that this is sufficient to accurately determine the presence/absence of the symbol. If present, I create a BeautifulSoup object for index 1 and then extract the first rel attribute, to get the symbol. I pair that with index 3 value in a tuple with the comprehension to end up with a list of tuples. I extend a global list with that returned list of tuples, each time through the loop over the global list keys.
Finally, I convert that list of tuples to a dictionary. This assumes that there are not repeated symbols across different requests. If there can be repeated potential keys within the global list of tuples you will need to amend the logic to capture the parent ETF and then decide how to handle.
import re
import json
import requests
from bs4 import BeautifulSoup as bs
def main(url):
with requests.Session() as req:
req.headers.update(headers)
for key in keys:
r = req.get(url.format(key))
print(f"Extracting: {r.url}")
data = json.loads(re_object.search(r.text).group(1))
values.extend([(bs(i[1], 'lxml').select_one('[rel]')['rel'], i[3])
for i in data if ' rel="' in i[1]])
keys = ['ARKK', 'VPOP']
headers = {"User-Agent": "Mozilla/5.0"}
values = []
re_object = re.compile(r'etf_holdings\.formatted_data = (\[.*?\]);')
main("https://www.zacks.com/funds/etf/{}/holding")
ticker_weights = dict(values)
print(ticker_weights)