Looking for non fancy, easily debugable for junior developer solution...
In SQL Server 2008 R2, I have to update data from #data table to #tests table in desired format. I am not sure how I would archive result using T-SQL query?
NOTE: temp tables have only 3 columns for sample purpose only but real table have more than 50 columns for each set.
Here is what my tables look like:
IF OBJECT_ID('tempdb..#tests') IS NOT NULL
DROP TABLE #tests
GO
CREATE TABLE #tests
(
id int,
FirstName varchar(100),
LastName varchar(100),
UniueNumber varchar(100)
)
IF OBJECT_ID('tempdb..#data') IS NOT NULL
DROP TABLE #data
GO
CREATE TABLE #data
(
id int,
FirstName1 varchar(100),
LastName1 varchar(100),
UniueNumber1 varchar(100),
FirstName2 varchar(100),
LastName2 varchar(100),
UniueNumber2 varchar(100),
FirstName3 varchar(100),
LastName3 varchar(100),
UniueNumber3 varchar(100),
FirstName4 varchar(100),
LastName4 varchar(100),
UniueNumber4 varchar(100),
FirstName5 varchar(100),
LastName5 varchar(100),
UniueNumber5 varchar(100),
FirstName6 varchar(100),
LastName6 varchar(100),
UniueNumber6 varchar(100),
FirstName7 varchar(100),
LastName7 varchar(100),
UniueNumber7 varchar(100)
)
INSERT INTO #data
VALUES (111, 'Tom', 'M', '12345', 'Sam', 'M', '65432', 'Chris', 'PATT', '54656', 'Sean', 'Meyer', '865554', 'Mike', 'Max', '999999', 'Tee', 'itc', '656546444', 'Mickey', 'Mul', '65443231')
INSERT INTO #data
VALUES (222, 'Kurr', 'P', '22222', 'Yammy', 'G', '33333', 'Saras', 'pi', '55555', 'Man', 'Shey', '666666', 'Max', 'Dopit', '66666678', '', '', '', '', '', '')
INSERT INTO #data
VALUES (333, 'Mia', 'K', '625344', 'Tee', 'TE', '777766', 'david', 'mot', '4444444', 'Jeff', 'August', '5666666', 'Mylee', 'Max', '0000000', '', '', '', 'Amy', 'Marr', '55543444')
SELECT *
FROM #data
I want to insert/update data into #tests table from #data table. Insert data into #tests table if id and UniqueNumber combination does not exists from #data table. If combination exists then update data into #tests table from #data table
This is desired output into #tests table
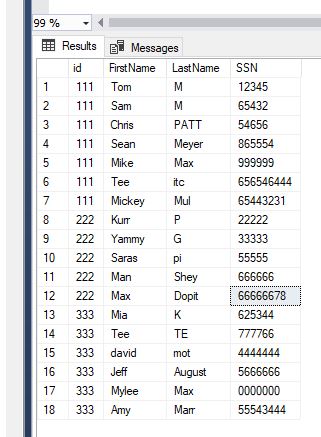
CodePudding user response:
One way is to query each group of columns separately and UNION the results
SELECT
id int,
FirstName1 as FirstName,
LastName1 as LastName,
UniueNumber1 AS SSN
FROM #data
UNION
SELECT
id int,
FirstName2 as FirstName,
LastName2 as LastName,
UniueNumber2 AS SSN
FROM #data
UNION
...
There's not a way to cleanly "loop through" the 7 groups of columns - you'll spend more time building a loop to create the query dynamically than just copying and pasting the query 6 times and changing the number.
Of course, it's best to avoid the type of structure you have in #data now if at all possible.
CodePudding user response:
Here is an option that will dynamically UNPIVOT your data without using Dynamic SQL
To be clear: UNPIVOT would be more performant, but you don't have to enumerate the 50 columns.
This is assuming your columns end with a NUMERIC i.e. FirstName##
Example
Select ID
,FirstName
,LastName
,UniueNumber -- You could use SSN = UniueNumber
From (
SELECT A.ID
,Grp
,Col = replace([Key],Grp,'')
,Value
FROM #data A
Cross Apply (
Select [Key]
,Value
,Grp = substring([Key],patindex('%[0-9]%',[Key]),25)
From OpenJson( (Select A.* For JSON Path,Without_Array_Wrapper ) )
) B
) src
Pivot ( max(Value) for Col in ([FirstName],[LastName],[UniueNumber]) ) pvt
Order By ID,Grp
Results
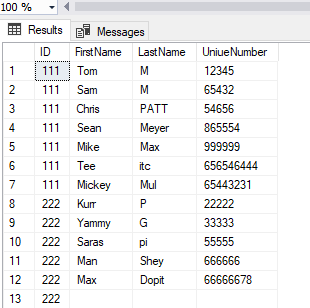
UPDATE XML Version
Select ID
,FirstName
,LastName
,UniueNumber
From (
SELECT A.ID
,Grp = substring(Item,patindex('%[0-9]%',Item),50)
,Col = replace(Item,substring(Item,patindex('%[0-9]%',Item),50),'')
,Value
FROM #data A
Cross Apply ( values (convert(xml,(Select A.* for XML RAW)))) B(XData)
Cross Apply (
Select Item = xAttr.value('local-name(.)', 'varchar(100)')
,Value = xAttr.value('.','varchar(max)')
From B.XData.nodes('//@*') xNode(xAttr)
) C
Where Item not in ('ID')
) src
Pivot ( max(Value) for Col in (FirstName,LastName,UniueNumber) ) pvt
Order By ID,Grp